
A 512-bit AVX-512 pipeline was one of the most significant upgrades AMD implemented into its Zen 5 CPU architecture — and, as a result — its Ryzen 9000 series CPUs. Phoronix published benchmark results of the new Ryzen 9 9950X in AVX-512 to see how much more performant and efficient Zen 5's AVX-512 capabilities are compared to the prior generation Ryzen 9 7950X.
Phoronix tested 90 applications and benchmarks in Linux, featuring the Ryzen 9 9950X and Ryzen 9 7950X. Both chips were benchmarked with AVX-512 on and off to see the performance and power efficiency differences each chip gains or loses with AVX-512 acceleration.
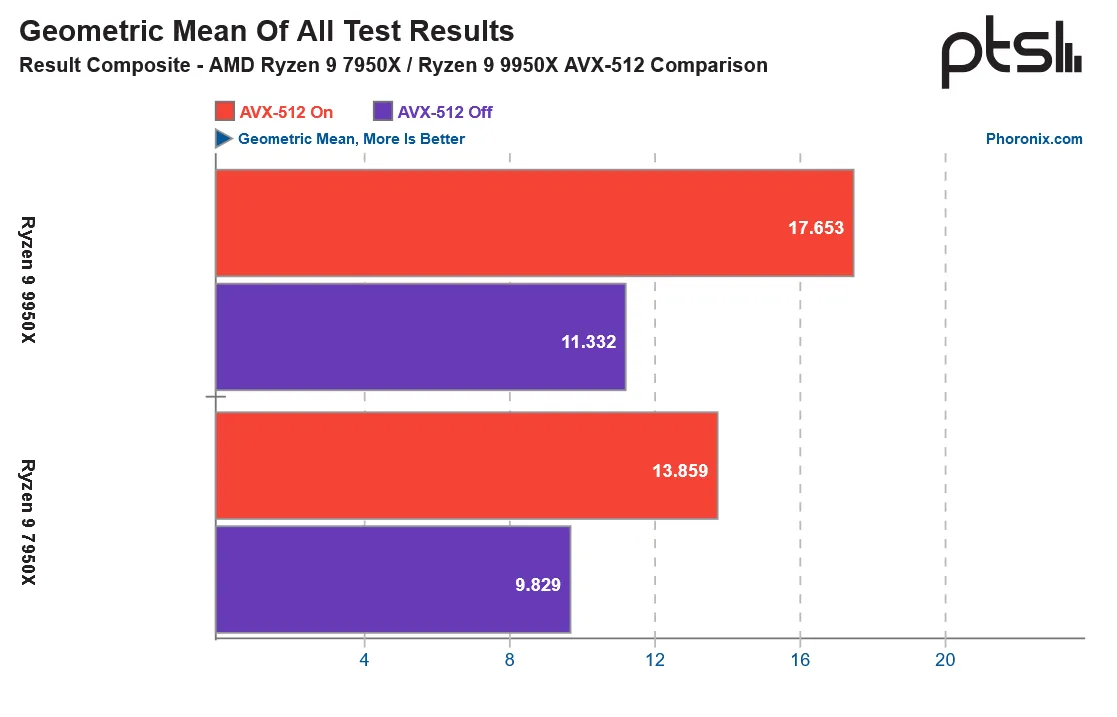
In the 90 benchmarks tested, the Ryzen 9 9950X saw an overall performance gain of 27% compared to the Ryzen 9 7950X with AVX turned on. Disabled, the margins were much narrower, with the 9950X outperforming the 7950X by 15%.
On vs. off, the Ryzen 9 9950X impressively gained 56% more performance on average across all benchmarks compared to having AVX-512 acceleration turned off. The 7950X similarly saw a still impressive 41% performance improvement with AVX-512 acceleration turned on vs off.
Phoronix also saw excellent power efficiency with the new Ryzen 9 9950X. Despite having a full-blown AVX-512 pipeline, the Zen 5 chip only consumed a couple more watts at full load than the AVX-512 disabled. On average, the 9950X consumed 205.19 watts at its peak with AVX-512 acceleration turned on. Turned off, the chip consumed 203.94 watts.
The Ryzen 9 7950X outperforms the 9950X in this specific measurement. Turning AVX-512 on or off Zen 4 does not incur any peak wattage improvement or regression. However, the chip consumed noticeably more power overall than the 9950X.

Because the chip's excellent power efficiency in AVX-512 workloads resulted in very few differences in frequency and CPU temperatures on the 9950X, utilizing AVX-512 made the 9950X run at slightly higher clock speeds and slightly lower temperatures. The 7950X saw virtually no change in CPU thermals or clock speeds.
Phoronix's testing confirms that AMD has a very performant and highly power-efficient AVX-512 implementation in Zen 5. Zen 5 is the first AMD architecture with an entire AVX-512 pipeline featuring a 512-bit data path. Zen 4 was technically the first AMD architecture to support AVX-512. Still, AMD cleverly reused its existing AVX-256 pipeline to run AVX-512 instructions in what's known as a dual-issue AVX-512 pipeline that "double pumps" instructions to achieve AVX-512 acceleration functionality.
Zen 5's AVX-512 is the best implementation of AVX-512 acceleration we have ever seen, a far cry from Intel's adaptation in its older architectures. When AVX-512 first came out on Intel CPUs, supported Intel chips had to sacrifice a significant amount of clock speed when running AVX-512 instructions while also consuming a ton of power. Zen 5 is the complete opposite and can—still, AMDpeak boost clocks in AVX-512 workloads.
