





















As important as it is to keep your disks clear of duplicate files, finding copies of files is a tiresome job and most people don’t want to do it. This isn’t a problem if all you have are tiny text files that take up a few kilobytes each. But media files, especially raw images and HD videos can eat a lot of disk space, leaving you with less room for new data and apps.
Thankfully, the Fdupes command-line utility provides a faster and more efficient way of identifying duplicate files than just manually combing through your folders. Released under the MIT License, this nifty tool can be used to find duplicate files in the specified directories. The tool works by comparing the MD5 signature of the files, followed by a byte-to-byte comparison to ensure that all copies are identified.
In addition to tracking down duplicates, you can also use Fdupes to delete duplicate files, replace deleted files with links to the original, etc.
How to Install Fdupes for Linux
You’ll find Fdupes in the software repositories of most desktop distributions such as Ubuntu, Fedora, Arch, etc. The following instructions work on Ubuntu, Debian and other Linux flavors that are based on them (ex: Mint and Raspberry Pi OS).
1. Update the list of repositories by entering this command in a terminal window.
$ sudo apt update2. Install the dependencies and npm package manager.
sudo apt install fdupesYou can similarly install Fdupes on Fedora, or other rpm based distributions with the ///BEGIN CODE///sudo dnf install fdupes///END CODE/// command.
How to Find Duplicate Files in Linux with Fdupes
Despite performing a seemingly straightforward task, Fdupes boasts of a vast number of useful features. As the utility can also be used to delete duplicate files, we would advise you to spend some time with the man page to familiarise yourself with the different command options. At a minimum, Fdupes expect the path to a directory to perform a search for duplicates.
$ fdupes </path/to/directory>- To identify duplicate files in a given directory:
Refer the directory to fdupes
$ fdupes ~/Documents
- To recursively search through all sub-directories in the specified directory and identify all the duplicate files.
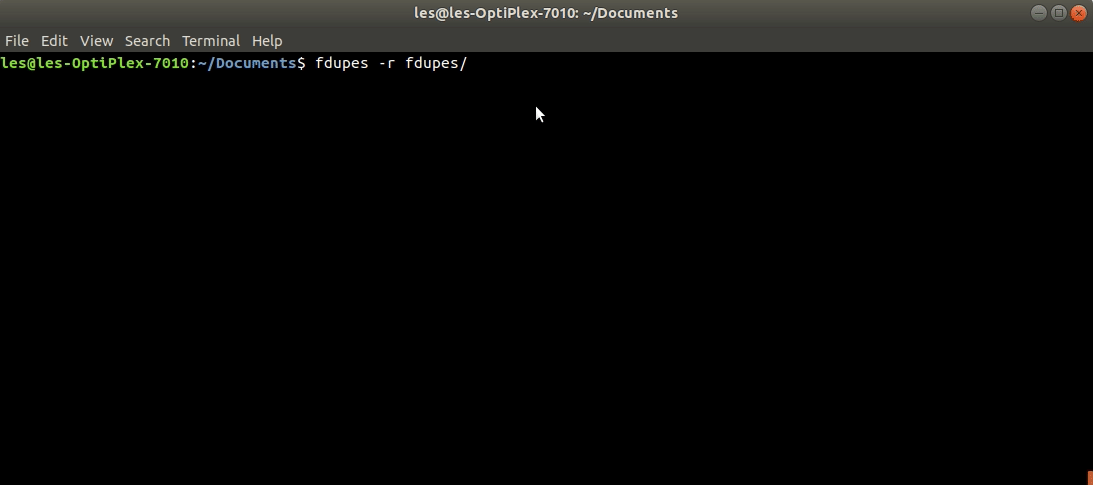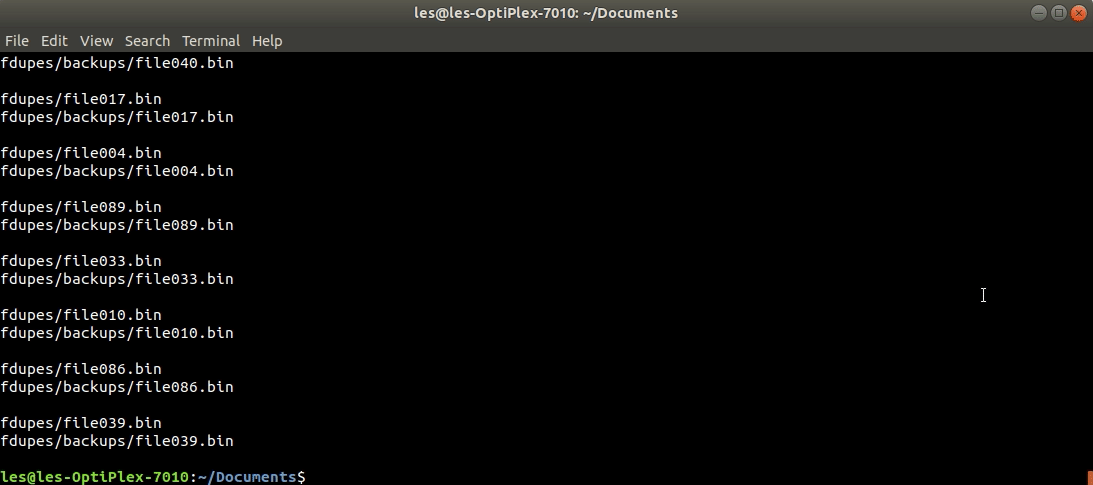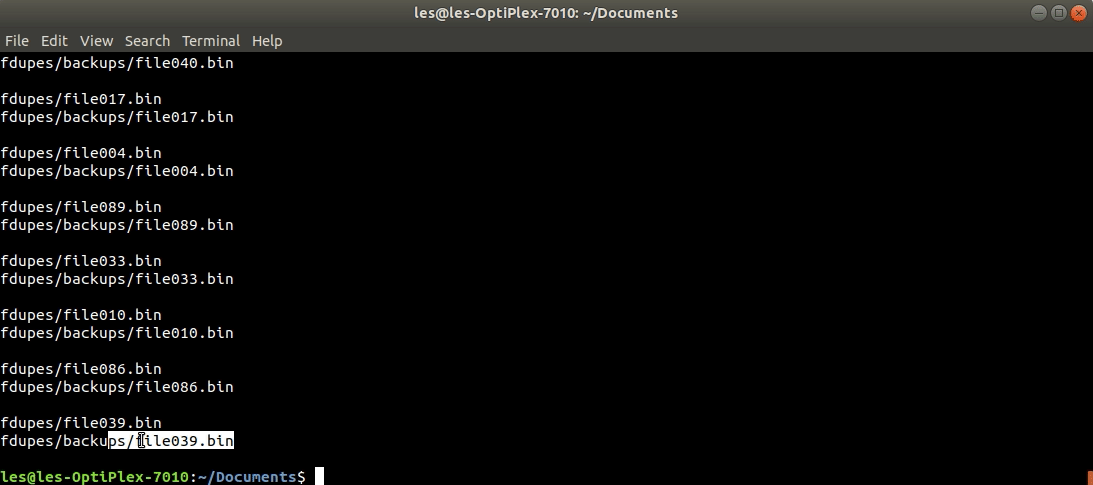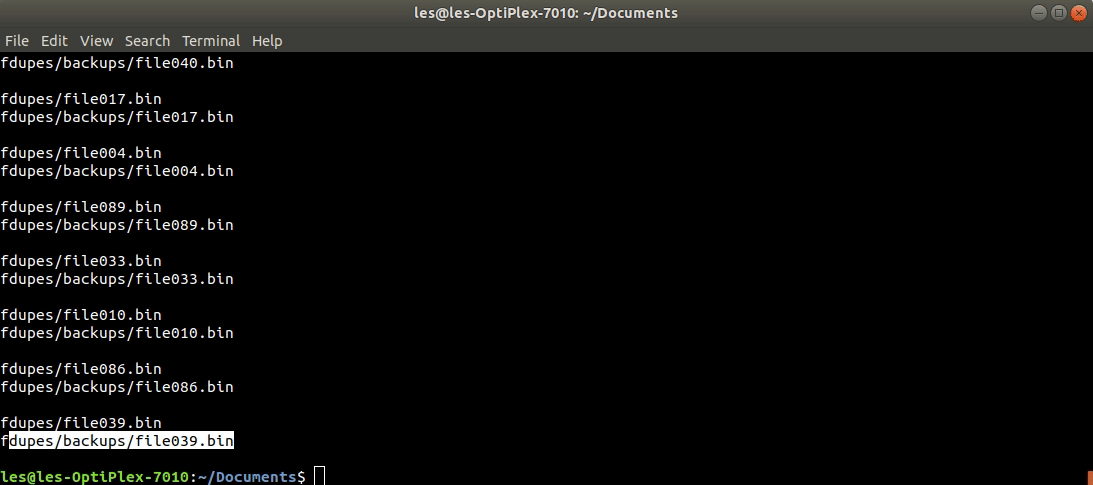
$ fdupes -r ~/DocumentsBoth the above commands only list the duplicate files onto the screen, without deleting them. You must use the -d command option if you want Fdupes to also delete the duplicate files it identifies. But even then, Fdupes will ask to confirm which of the identified files you wish to retain. You can choose to keep a single file, or provide a comma separated list of the ones you wish to retain, or alternatively to keep all.

Here we've opted to retain two files. Also, if your specified directory has multiple copies of different files, each group of copies of a single file is referred to as a set.
This is only a basic introduction to Fdupes. There’s still more that you can do such as ignore hidden files or follow symbolic links, etc.
More Linux Tutorials:
