






















Nvidia announced the H200 and GH200 product line at Supercomputing 23 this morning. These are the most powerful chips Nvidia has ever created, building on the existing Hopper H100 architecture but adding more memory and more compute. These are set to power the future generation of AI supercomputers, with over 200 exaflops of AI compute set to come online during 2024. Let's dig into the details.
The H200 GPU is perhaps the real star of the show. Nvidia didn't provide a detailed breakdown of all the specifications, but the major point appears to be a significant increase in memory capacity and bandwidth per GPU.

The updated H200 features 141GB total of HBM3e memory, running at around 6.25 Gbps effective, for 4.8 TB/s of total bandwidth per GPU across the six HBM3e stacks. That's a massive improvement over the original H100, which had 80GB of HBM3 and 3.35 TB/s of bandwidth. Certain configurations of H100 did offer more memory, like the H100 NVL that paired two boards and provided an aggregate 188GB of memory (94GB per GPU), but compared to the H100 SXM variant, the new H200 SXM offers 76% more memory capacity and 43% more bandwidth.
Note that raw compute performance doesn't appear to have changed much. The only graphic Nvidia showed for compute used an eight GPU HGX 200 configuration with "32 PFLOPS FP8" as the total performance. The original H100 offered 3,958 teraflops of FP8, so eight such GPUs already provided roughly 32 petaflops of FP8.
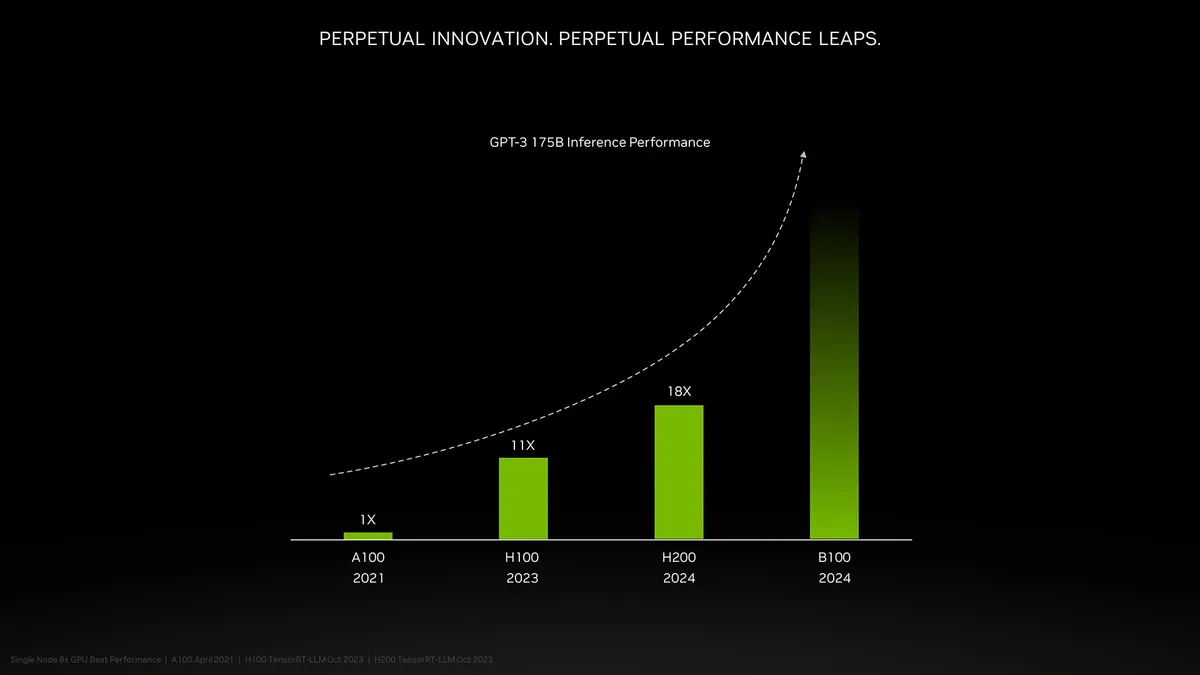
How much faster will H200 be compared to H100? That will depend on the workload. For LLMs like GPT-3 that greatly benefit from increased memory capacity, Nvidia claims up to 18X higher performance than the original A100, whereas the H100 is only about 11X faster. There's also a tease of the upcoming Blackwell B100, though right now that only consists of a higher bar that fades to black.

Naturally, this isn't just an announcement of the updated H200 GPU. There's also a new GH200 coming down the pipeline, which combines the H200 GPU with the Grace CPU. Each GH200 "superchip" will contain a combined 624GB of memory. The original GH100 combined 480GB of LPDDR5x memory for the CPU with 96GB of HBM3 memory, while the new iteration uses the previously discussed 144GB of HBM3e.
Again, details on whether anything else has changed with the CPU side of things are sparse, but Nvidia provided some comparisons between GH200 and a "modern dual-socket x86" configuration — take with loads of salt, as there was a mention of the speedup versus "non-accelerated systems."
What does that mean? We can only assume that the x86 servers were running less-than-fully-optimized code, especially given that the AI world is fast moving and there seem to be new advances in optimizations on a regular basis.

The GH200 will also be used in new HGX H200 systems. These are said to be "seamlessly compatible" with the existing HGX H100 systems, meaning HGX H200 can be used in the same installations for increased performance and memory capacity without having to rework the infrastructure — which brings up the final discussion of new supercomputers that will be powered by GH200.
The Alps supercomputer from the Swiss National Supercomputing Center will likely be one of the first Grace Hopper supercomputers to go live in the next year. That still uses GH100. The first GH200 system to go live in the U.S. will be the Venado supercomputer from Los Alamos National Laboratory. The Texas Advanced Computing Center (TACC) Vista system will likewise use Grace CPUs and Grace Hopper superchips, which was announced today, but it's not clear if those are H100 or H200.
The biggest upcoming installation, as far as we're aware, is the Jupiter supercomputer from the Jϋlich Supercomputing Centre. It will house "nearly" 24,000 GH200 superchips, with a combined 93 exaflops of AI compute (presumably that's using the FP8 numbers, though most AI still uses BF16 or FP16 in our experience). It will also provide 1 exaflop of traditional FP64 compute. It uses "quad GH200" boards that feature four GH200 superchips.
All told, Nvidia expects over 200 exaflops of AI computational performance to come online during the next year or so with these new supercomputer installations. You can view the full Nvidia presentation below.

