Intel To Develop A Sun-Blocker?
The base line for Intel's internal analysis is Sun's Niagara (UltraSPARC T1) processor. It is a 90 nm, single-die, eight core 1.2 GHz server-type processor with four threads per core, four L2 caches (3 MB) that can all be accessed via a crossbar interface, four dual-channel DDR2-400 memory interfaces and a total of 279 million transistors at 379 mm² die size. All of this comes at a low 72 W peak power consumption, making such a product a serious threat.
We assume that a single Niagara processor is approximately twice as fast as a dual processor, dual core Woodcrest setup that Intel delivers today (eight 1.2 GHz cores vs. four 3 GHz cores). According to Intel's competition analysis, future 65 and 45 nm Niagara-type processors might double the thread count and L2 cache size with each generation, while upgrading to latest memory technologies. Intel wants to be prepared and believes that a well-structured, multi-core approach with a smart L3 cache design can block Sun.
Keifer Carries 32 Cores in 8 Nodes
Intel's most important weapon probably is its advanced manufacturing. It has been using the 65 nm process for almost a year, while AMD and Sun are in the transition process. If you now assume that Intel will reach 45 and 32 nm well ahead again, it could deploy a larger core count and more cache than the competitor.
As the chart on the first page of this article shows, Intel expects the jump from eight to 16 cores to provide a 50% performance improvement. Project Keifer, which would be a complete redesign and directly go to 32 cores, may provide a whopping 100% performance jump when compared to a 16-core processor in 2010.
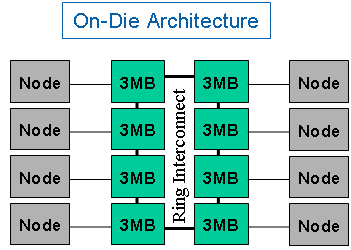
The key for these wet dreams is a modular design approach that is based on eight processing nodes, each carrying a common 3 MB L2 cache (24 MB total) and four processor cores with 512 kB shared L2 cache. A ring interconnect, similar to what ATI deployed in its Radeon X1900 memory subsystem, will provide quick communication between the nodes.
le
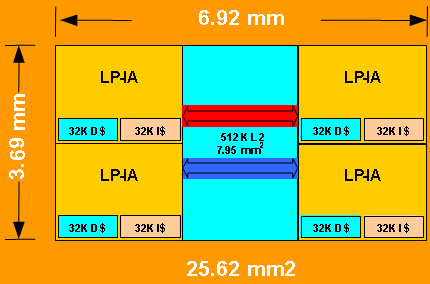
Each Keifer node will carry four cores at 32 kB data and 32 kB instruction cache as well as a 512 kB L2 cache. The limitation to this node L2 cache capacity seems to provide better performance than fewer cores with larger caches.
