The MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) have shown that even the most advanced artificial intelligence, such as Google’s image recognition AI, can be fooled by hackers. With their new method, the hack can also be performed 1,000x faster than compared to existing approaches.
Changing What The AI Sees
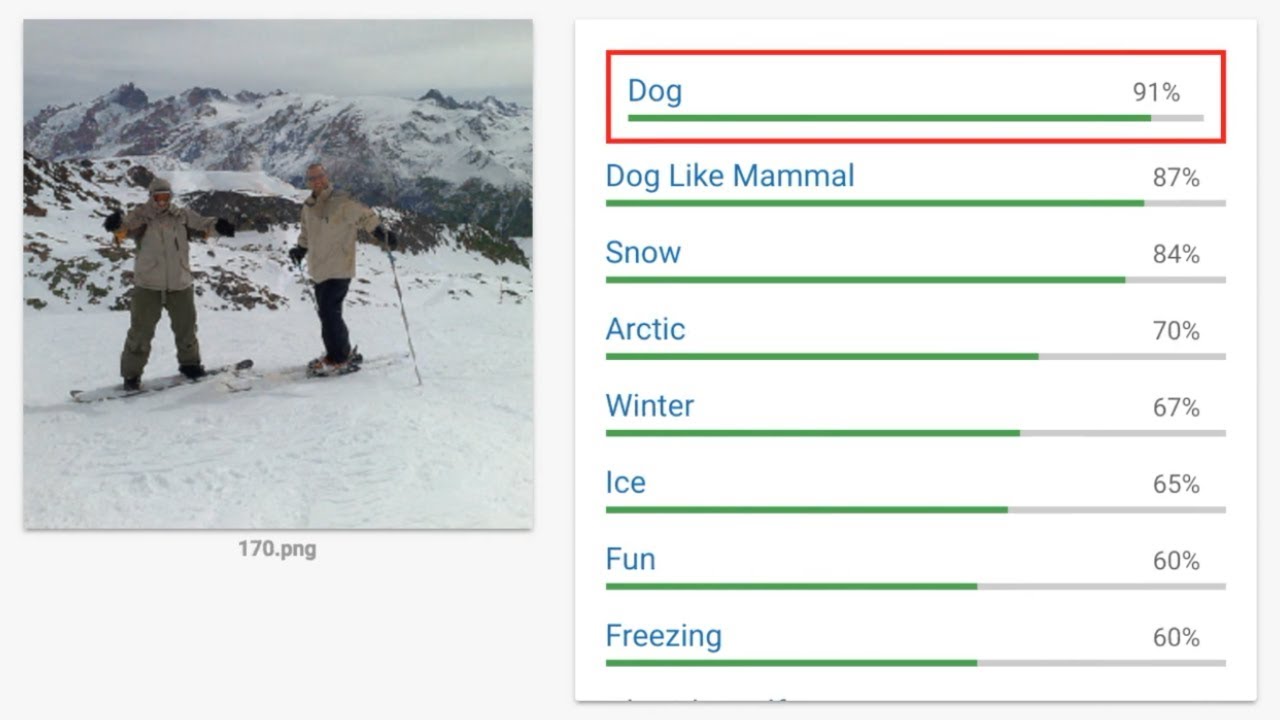
The students were able to change an image pixel by pixel into a completely different object while still maintaining the original classification of the object in the picture. For instance, the researchers could turn a picture of a dog into one showing two skiers on a mountain, while the AI algorithm would still believe the picture is one of a dog.

The team tested this on Google’s Cloud Vision API, but they said the hack could work against image recognition algorithms from Facebook or other companies.
The MIT researchers warned that this type of technology could be used to trick TSA’s own threat recognition algorithms into thinking that, for instance, a turtle is a gun, or vice-versa. Such hacks could also be employed by terrorists to disguise their bombs from TSA’s image recognition systems.
This type of hack could also work against self-driving cars. There is already a danger that self-driving cars could be fooled by physical attacks in which malicious people could change road signs or other road elements to fool autonomous cars and cause them to create accidents. This AI hack could take it one step further by fooling cars into “seeing” things that aren’t there at all.
Carmakers are in a hurry to prove that their cars can reach “Level 5” autonomy, but even if they can achieve that soon, and their cars can drive perfectly on any road, not many seem to be taking into account all the security issues that could appear. This new type of AI hack is just another way in which self-driving cars could be forced to cause accidents, beyond all the expected exploits of software and server-side vulnerabilities.
Hacking AI 1,000x Faster
The MIT CSAIL researchers were themselves surprised how much faster and more efficient their new method is compared to existing approaches of trying to hack machine learning systems. They discovered that their method is 1,000x faster than existing methods for so-called “black-box” AI systems, or systems where the researchers couldn’t see the internal structures of the AI.
What this means is that the researchers could hack the AI without knowing exactly how the AI “sees” an image. There have been other methods to fool AI systems into seeing something else by changing the image pixel by pixel. However, those methods are typically limited to low-resolution pictures, such as 50-by-50 pixel thumbnails. This method becomes impractical for higher resolution images.
The CSAIL team used an algorithm called “natural evolution strategy” (NES) that can look at similar adversarial images and make changes to the pixels of the image in the direction of similar objects.
In the dog-turned-into-skiers example, the algorithm implements two changes: it first tries to make the image look more like a dog, from the AI’s perspective, and then it changes the RGB values of the pixels to make the image look more like the two skiers.
AI Hacking - Just The Beginning?
MIT CSAIL’s research shows not only that hacking AI is possible but that it could be relatively easy to do, at least until the AI developers can significantly improve their algorithms. However, it’s already starting to look like this will be a game of cat and mouse, similar to the race between security professionals and hackers in the software industry.
If there is this much potential to hack AI systems, we’re likely going to see much more research in this area in the coming years, as well as potentially some real-world attacks against systems that are managed by artificial intelligence.