Is Pipelining Important
Rambus seems to look very good under deeply pipelined conditions. Deep pipelining can allow Rambus to achieve and sustain an extremely high rate of bus utilization. For instance, if the transactions are deeply pipelined, Rambus can sustain transfer rates of up to 1.5 GB/s (or around 95% of it theoretical maximum peak burst rate of 1.6 GB/s). This is truly an amazing feat for a DRAM and for the system as a whole. SDRAM cannot achieve this level of saturation, nor can a single well cached CPU under most circumstances.
The diagram below shows how pipelining works on the P6 bus. Direct Rambus operates in a similar manner. By allowing different groups of bus signals to operate independently, new transactions are able to begin while previous transactions are still in progress. Using the P6 bus in multiprocessor mode, the diagram below shows how transactions from processors A, B & C can be pipelined on the CPU bus in a very tight sequence.
When transactions are pipelined this tightly, the data bus will burst out data continuously on every clock edge. If you look only at the bottom line (Data), after the latency period for transaction A has passed, all other latencies are hidden. But this does not mean "zero latency". In fact all requests still experience a rather long latency of at least 9 CPU bus clocks from the time a request appears on the bus until it is resolved.
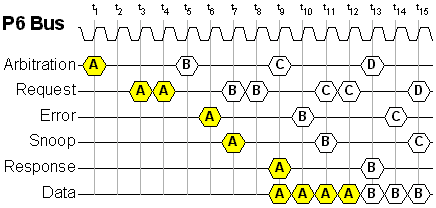
In order to achieve this elusive state of 100% bus utilization, there will usually be a deep queue of transactions buffered inside of the CPU (or CPUs). These internally buffered transactions will have an even higher effective latency due to the additional waiting period inside the CPU. Thus, high bus saturation (via deep pipelining) is an indication of wasted MIPS. This may be perfectly acceptable in servers that have plenty of MIPS to waste, but uniprocessor systems are different.