More Cash For Your Cache!
The ambitious user will wonder why Intel did not raise the speed, as it did for the P4 with 3.2 GHz. Instead, the company attached an additional L3 cache. This is the method that Intel uses to raise the performance of the processor in certain applications, while leaving the CPU design practically untouched. Our benchmarks and an extensive discussion in this article will shed some light on whether or not it meets expectations. In any case, the size of the die turns out to be much bigger compared to the version without a third cache. Also, theoretically, Intel could have raised the L2 cache from 512 kB to 1024 kB, bringing it closer to the Prescott or Nocoma design. In principle, the three cache levels of the Xeon differ not only in size but in access latency times as well. However, they work with full processor speed - in our case, with 3.06 GHz. At this point we would like to show you a graphic from Intel.
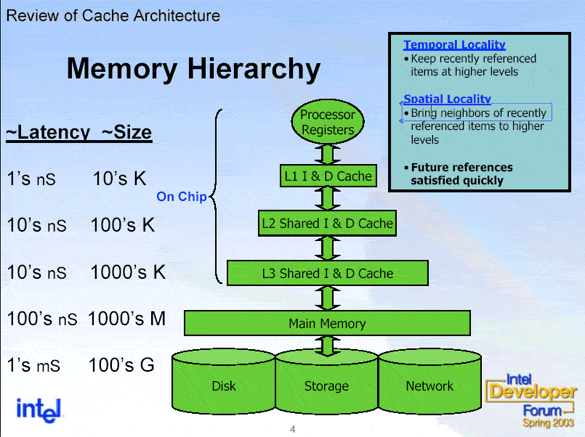
This is the way Intel explains how the individual cache levels work. The latency times of the associated caches are crucial.
It can be seen in the picture how different the latency times of the individual caches are in theory. No detailed information was forthcoming when Intel was asked about the values for the L2 and L3 caches. From a purely mathematical point of view, the L3 cache would have to operate more slowly than the L2 cache, which is half its size and faster. Otherwise making the L2 cache bigger would have been more effective - although also more expensive. There is also the risk that a larger L2 cache with the same CPU architecture will not provide the desired boost in speed. This is a good place to mention the transition from the Willamette P4 to the Northwood P4. Doubling the L2 cache from 256 kB to 512 kB alone did not provide the big increase in performance. It was only possible to enhance performance in combination with a higher bandwidth (FSB speed). With the Xeon, the manufacturer pursues another scheme: the 1 MB L3 cache is intended to push off the slow access to the local memory.