TurboCache - It's Bandwidth, But Not As We Know It
A special driver, called TCM (TurboCache Manager), handles the allocation of system memory for the card, dynamically determining the amount of system memory needed at any given time. Thanks to its MMU (Memory Management Unit), the graphics processor is able to write directly to the system's memory and to fetch data from it. The amount of memory that will be allocated to the card varies, depending on the size of the card's local memory and the memory requirements of the 3D application in question. The dynamic allocation also influences the card's speed.
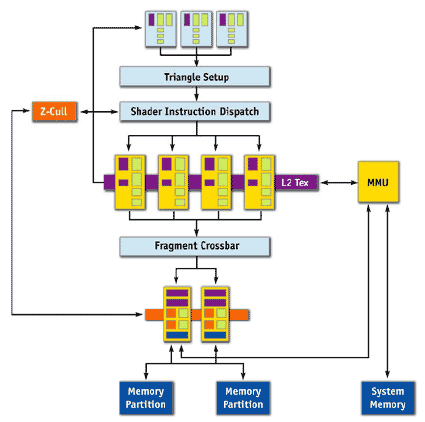
The Architecture behind TurboCache.
Despite only being physically equipped with 16 MB or 32 MB of local memory, this allows TurboCache cards to access a frame buffer of up to 128 MB, and even 256 MB in the case of the 64 MB model. However, the PC needs to have at least 512 MB of RAM installed for this to work. As soon as a 3D application is shut down, the areas reserved for the graphics cards are made available to the system again.
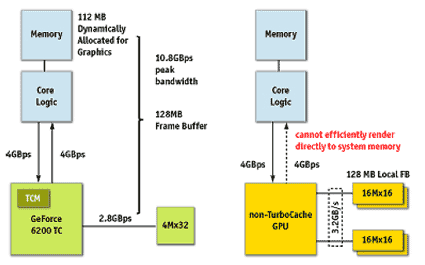
The diagram on the left shows a 16 MB TurboCache card. Next to it you can see that of a conventional graphics card with 128 MB of dedicated, local memory.
The PCI Express bus is used to connect the card to the system's memory and offers a peak data transfer rate of 4 GB/s. Since this bandwidth is available in both directions (full-duplex = from the card to the Northbridge and vice versa), optimists like to quote the cumulative bandwidth of PCI Express as being 8 GB/s. Of course, shuffling numbers changes nothing about the fact that effectively, only 4 GB/s are actually available for data transfers over the bus.

The peak bandwidth quoted here is quite optimistic. Several different bandwidths have been added to arrive at this number.
Nvidia's formula for calculating the memory bandwidth of TurboCache cards is as follows: The local memory of a GeForce 6200 TurboCache TC-16/128 card with a 32 Bit bus running at 350 MHz offers a peak bandwidth of 2.8 GB/s. To this, Nvidia adds the (theoretically possible) 8 GB/s of the PCI Express bus for a grand total of 10.8 GB/s. Obviously, this number is not derived in the same way as the memory bandwidth specifications we are used to with previously-available graphics cards.
In truth, the memory bandwidth is closer to 2.8 (local)/ 4 (PCIe) GB/s for the TC-16/128 card (16 MB of local memory) and 5.6/4 GB/s for the TC-32/128 card (32 MB). Another aspect that needs to be taken into account as well is system memory throughput. On modern motherboards using DDR 400 RAM, memory throughput is 6.4 GB/s. In theory, this is easily sufficient. However, in practice, the PC will also be making use of this bandwidth. As a result, the TurboCache cards will end up competing for bandwidth with the remaining components.

Intel's 9x5 chipset doesn't deliver the full theoretical PCI Express bandwidth.
TurboCache cards may also run into trouble on Intel-powered PCI Express systems. As Nvidia points out, Intel's current 915/925 chipsets don't offer the full theoretical PCI Express bandwidth. Instead of providing two times 4 GB/s (see above), they can only read at 3 GB/s and write at 1 GB/s. Our direct comparisons between Intel's 915 chipset and Nvidia's nForce 4 backed up this claim, showing lower PCI Express performance on the Intel system in some cases in conjunction with the GeForce 6200 TC (see benchmarks).













