Why you can trust Tom's Hardware Our expert reviewers spend hours testing and comparing products and services so you can choose the best for you. Find out more about how we test.
All systems are tested in a dual socket (2P) configuration.
| Test Platform | Memory | Tested Processors |
|---|---|---|
| 2P AMD Titanite Reference Platform | 24x 64GB (1.5TB) Samsung ECC DDR5-4800 | AMD EPYC Genoa 9654, 9554, 9374F |
| 2P AMD Daytona Reference Platform | 16x 32GB (512GB) Micron DDR4-3200 | AMD EPYC Milan 7763, 75F3 |
| 2P Intel S2W3SIL4Q Reference Platform | 16x 32GB SK hynix ECC DDR4-3200 | Intel Xeon Platinum 8380 |
| Model | Price | Cores/Threads | Base/Boost (GHz) | TDP | L3 Cache (MB) | cTDP (W) |
|---|---|---|---|---|---|---|
| EPYC Genoa 9654 | $11,805 | 96 / 192 | 2.4 / 3.7 | 360W | 384 | 320-400 |
| EPYC Genoa 9554 | $9,087 | 64 / 128 | 3.1 / 3.75 | 360W | 256 | 320-400 |
| EPYC Milan 7763 | $7,890 | 64 / 128 | 2.45 / 3.5 | 280W | 256 | Row 2 - Cell 6 |
| Xeon Platinum 8380 | $9,359 | 40 / 80 | 2.3 / 3.2 - 3.0 | 270W | 60 | Row 3 - Cell 6 |
| EPYC Genoa 9374F | $4,850 | 32 / 64 | 3.85 / 4.3 | 320W | 256 | 320-400 |
| EPYC Milan 7F53 | $4,860 | 32 / 64 | 2.95 / 4.0 | 280W | 256 | Row 5 - Cell 6 |
Molecular Dynamics and Parallel Compute Benchmarks




NAMD is a parallel molecular dynamics code designed to scale well with additional compute resources; it scales up to 500,000 cores and is one of the premier benchmarks used to quantify performance with simulation code. The 32-Core EPYC 9374F sets the tone for what we'll see throughout many of these benchmarks, as it easily beats the Ice Lake 8380s.
Yes, price tags are largely a mirage in the server world, but it bears mentioning that the 9374F has a suggested $4,850 price tag, while the 8380 is still listed at $9,359 on Intel's site (though we doubt it has sold for that in a long time).
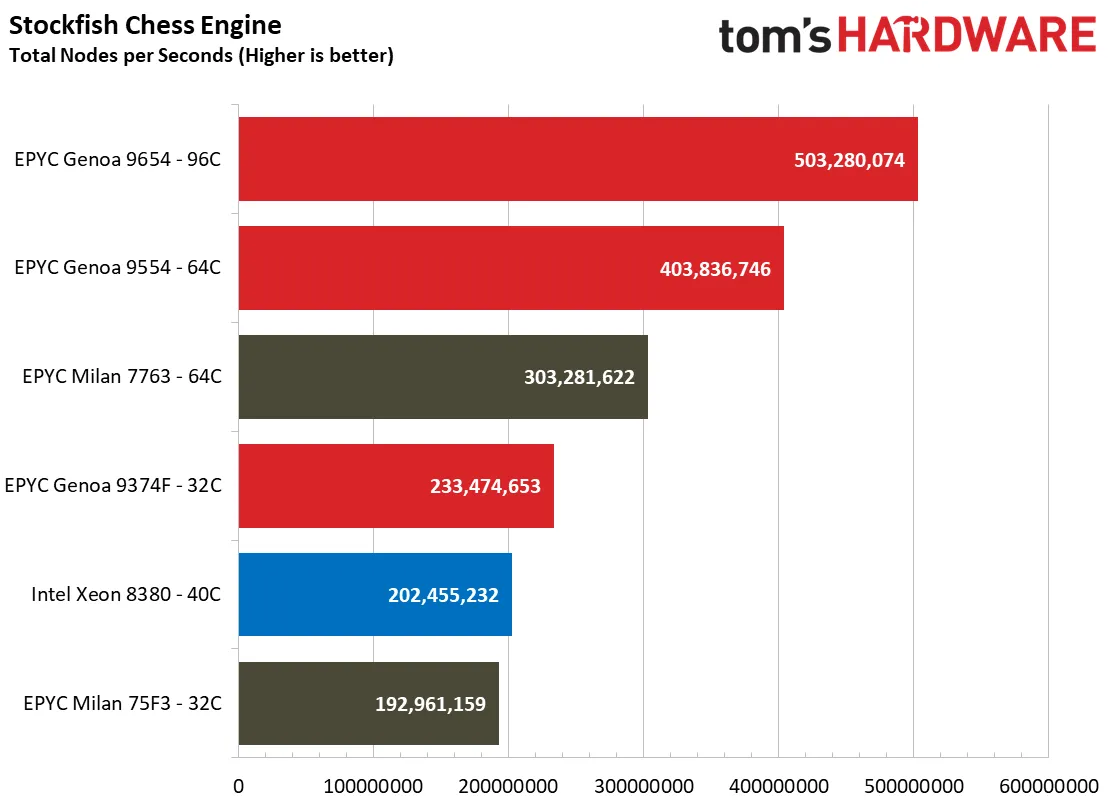
The award-winning Stockfish chess engine is designed for the utmost scalability across core counts — it can scale up to 512 threads (so we still have just a bit of scalability left before Bergamo arrives). Here we can see that this massively parallel code scales well with EPYC's leading core counts as the 96-core EPYC 9654 provides more than twice the amount of performance of the 8380s. Also, note the 64-core EPYC 9554's solid 33% increase over the previous-gen 64-core EPYC 7763. That big jump in performance makes the 15% gen-on-gen price increase for 64 cores feel a lot more palatable.
The Gromacs water benchmark simulates Newtonian equations of motion with hundreds of millions of particles. This workload scales well, but the fact is that many workloads will hit other bottlenecks, like memory throughput or power constraints, before they can fully leverage the 96-cores found on the EPYC 9654. As such, the 64-core EPYC 9554 nearly ties the 9654 in this compute-intensive workload.
We can also say much the same about the LAAMPS molecular dynamics code. While this code is inherently scalable, we're obviously reaching other bottlenecks before the full might of the 9654's cores can be unleashed.
Naturally, the big hyperscalers and tier-one OEMs will make sure that these exotic 96-core chips, which actually don't have exotic pricing given their capabilities, will find a home with workloads that can fully leverage the compute resources.
Rendering Benchmarks








Turning to the more standard fare, provided you can keep the cores fed with data, most modern rendering applications also take full advantage of the compute resources.
Intel developed Embree, a ray tracing kernel for CPUs that leverages the AVX-512 instruction set, but we don't use the Intel SPMD program compiler (ISPC) to keep things fair. In either case, the EPYC Genoa processors dominate these Intel-designed benchmarks. The 96-core EPYC 9654 provides more than twice the performance of the Intel platform, while the 64-core model provides a nearly linear performance scaling over its 32-core counterpart, the 9374F. That's impressive in its own right.
Moving on to compute-intensive ray tracing benchmarks, the Genoa chips stretch their legs in the Embree-based OSPray benchmark, once again highlighting the incredible imbalance that we'll see in the data center CPU market until Sapphire Rapids arrives.
Linux Kernel, LLVM, PHP, Godot Compilation Benchmarks






Sure, AMD's Genoa is brutal in multi-threaded workloads, so we shifted gears to compilation work to see how the chips handle more varied workloads. Regardless of the compilation tasks we threw at the chips, the Genoa chips provided substantial speedups over the previous-gen Milan chips and beat Intel convincingly. As you can see, frequency comes into play with this type of work, so the Genoa 9374F shows its agility as it chews through the compilation work. It's hard not to like this plucky chip, as it provides an impressive amount of threaded horsepower combined with great performance in frequency-sensitive workloads.
Compression, Security, NumPy and Python Benchmarks








The open-source OpenSSL toolkit uses SSL and TLS protocols to measure RSA 4096-bit performance in verify and sign operations, along with SHA-256 throughput. These heavily multi-threaded workloads are incredibly taxing — we measured up to 1600W of power consumption for the dual-socket Genoa 9654 configuration during these tests — so higher core counts tend to reign supreme if all other factors are equal. They aren't, though, and Genoa's per-core performance advantage powers the 32-core EPYC 9374F to somewhat stunning wins over the 40-core Ice Lake Xeon 8380's. Meanwhile, the 96- and 64-core Genoa models show just how far Intel lags behind the more modern Zen 4 architecture.
The Pybench and Numpy benchmarks are used as a general litmus test of Python performance, and as we can see, these tests typically don't scale linearly with increased core counts, instead prizing per-core performance. Here the 32-core EPYC Genoa 9374F reigns supreme, easily leveraging its superior clock speeds and copious cache to outmaneuver the heftier chips. That said, the 96- and 64-core Genoa models still impress as they outperform Ice Lake by significant margins.
Compression workloads come in many flavors. The 7-Zip (p7zip) benchmark exposes the heights of theoretical compression performance because it runs directly from main memory, allowing both memory throughput and core counts to impact performance heavily. As we can see, this benefits the core-heavy chips as they easily dispatch with the chips with lesser core counts. Intel's Ice Lake demonstrates how badly it already trailed Milan, and Genoa widens the chasm. Even Gzip, which we use to show compression performance with a more frequency-sensitive engine, finds the Xeon Platinum 8380's trailing the entire test pool.
Encoding Benchmarks



Encoders tend to present a different type of challenge: As we can see with the FLAC benchmark, they often don't scale well with increased core counts. Instead, they often benefit from per-core performance and other factors, like cache capacity. Intel's Ice Lake has 60MB of L3 cache, which is woefully inadequate compared to the 256MB and 384MB of L3 etched into the Genoa CCDs for these particular models.
- MORE: Best CPUs for Gaming
- MORE: CPU Benchmark Hierarchy
- MORE: AMD vs Intel
- MORE: Zen 4 Ryzen 7000 All We Know
