





















The Trace Cache Branch Prediction Unit

Intel is very proud on the branch prediction unit that aids the execution trace cache. Its branch target buffer is 8 times as large as the one found in Pentium III and its new algorithm is supposed to be way better than AMD's latest G-share algorithm used in Thunderbird and Spitfire. Intel claims that this unit can eliminate 33% of the mispredictions of Pentium III.
Hyper Pipeline

One of the most well known features of the new Pentium 4 is its extremely long pipeline. While the pipeline of Pentium III has 10 stages and the one of Athlon 11, Pentium 4 has no less than 20 stages.
The reason for the longer pipeline is Intel's wish of Pentium 4 to deliver highest clock rates. The smaller or shorter each pipeline stage, the fewer transistors or 'gates' it needs and the faster it is able to run. However, there is also one big disadvantage to long pipelines. As soon as it turns out at the end of the pipeline that the software will branch to an address that was not predicted, the whole pipeline needs to be flushed and refilled. The longer the pipeline the more 'in-flight' instructions will be lost and the longer it takes until the pipeline is filled again.
Intel is proud to announce that the Pentium 4 pipeline can keep up to 126 instructions 'in-flight', amongst them up to 48 load and 24 store operations. The improved trace cache branch prediction unit described above is supposed to ensure that flushes of this long pipeline are only rare occasions.
The stuff that happens in the trace cache, as mentioned above, only represents the first five stages of the pipeline of Pentium 4. What follows is
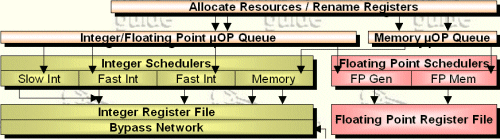
- Allocate resources
- Register renaming
- Write into the µOP queue
- Write into the schedulers and compute dependencies
- Dispatch µOPs to their execution units
- Read register file (to ensure that the correct ones of the 128 all-purpose register files are used as the register(s) for the actual instruction)
After that comes the actual execution of the µOP, which I will discuss more detailed in the next paragraph. Of the above-mentioned previous stages the schedulers as well as the register file read are the most interesting. I have still decided against discussing them in detail to keep this article from becoming my next book.
The Rapid Execution Engine

The above picture is actually showing all execution units of Pentium 4, including the 'Rapid Execution Engine' as well as the 'not-so-rapid' execution units. While Intel is only talking about the four fast execution units, the other four are the actual units that are responsible for Pentium 4's peculiar behavior in the benchmarks.
Basic part of the 'Rapid Execution Engine' are the two 'double-pumped' ALUs and AGUs. Each of the four is said to be clocked with double the processors clock, because they can receive a µOP every half clock. Intel never disclosed if those units are now indeed clocked with twice the processor clock or if each of those units is in reality consisting of two identical sub-units running at normal clock that can merely receive the µOPs alternately every half clock. It doesn't really matter which of the two is actually true, because the result is the same. Simple µOPs that can be processed by the Rapid Execution Engine are executed in half a clock, which is obviously a very good thing.
The story looks a lot different for the instructions that cannot be processed by the rapid execution units. Those instructions or µOPs need to use the one and only 'Slow ALU', which is not 'double pumped'. The majority of instructions needs to use this path, which obviously sounds scary. However, the majority of code is in actual fact consisting of the most simple 'AND', 'OR', 'XOR', 'ADD', .... Instructions, making Intel's 'Rapid Execution Engine'-design sensible though not particularly amazing.
Things look worse if you have a look at the red boxes, which represent the FPU-part of Pentium 4. Please take the time and compare this part to the Pentium III block diagram. You will see that Intel has actually castrated quite a bit of the SSE/MMX part of Pentium 4. Pentium III used to have two MMX and two SSE units, but Pentium 4 has only got one of each. Intel claims that additional units would not have improved the SSE/SSE2, MMX or FPU performance. However, our benchmark results speak a different language.
SSE2 - The New Double Precision Streaming SIMD Extensions
To conclude this epic piece about Pentium 4's internal architecture I need not forget to mention SSE2. 144 new instructions are finally enabling everything that SSE was expected to be in the first place. The 128 bit of packed data, which could only be in form of four single-precision floating-point values under SSE can now be operated in all of the following options:
- 4 single precision FP values (SSE)
- 2 double precision FP values (SSE2)
- 16 Byte values (SSE2)
- 8 word values (SSE2)
- 4 double word values (SSE2)
- 2 quad word values (SSE2)
- 1 128 bit integer value (SSE2)
The options are vast and the usefulness undoubted. Intel hopes that software developers will soon replace the old x87-FPU-instructions with the double-precision FP instructions of SSE2, so that Intel's currently false claim that Pentium 4 has the most powerful FPU finally becomes reality. AMD is very impressed with SSE2 as well, which is why it announced to us only a few days ago that the upcoming Hammer-line of x86-64 processors will include SSE2 as well.
I personally have my doubts if SSE2 will be able to replace x87-instructions in scientific software. We should not forget that the original FPU is using 80 bit FP-values, not the less exact 64 bit FP-values offered by SSE2.