





















Stepping Through The Architecture
Achieving this generation’s five design goals required notable tweaks to ATI’s architecture, though many of the cues are clearly taken from the Radeon HD 4800-series (and indeed the 3800-series before that).

Before we even get to the GPU’s shader processing capabilities, we have to take a look at the graphics engine, which includes ATI’s sixth-generation tessellation engine. We’ve seen the company evangelize tessellation in the past. But as with most things that only apply to one competitor, realization of this feature via actual games was limited. Now it’s part of the DirectX 11 pipeline, sandwiched on either side by the hull and domain shaders. The tessellator is a fixed-function component which can either be utilized or not, depending on the tessellation technique in play.
In its architectural description, AMD ambiguously claims to include dual rasterizers. As you probably know, current GPUs are capable of rasterizing a single triangle per cycle, and that very serial approach has become the main reason for the performance bottlenecks that show up in synthetic geometry tests on unified-shader architectures.
At first, we thought AMD had found a way to parallelize the setup, which would have been particularly well-suited to a GPU that places a lot of importance on tessellation. There are any number of options for rasterizing several triangles in parallel, but they’re very complex. So, we were curious to see how AMD had solved this puzzle. Unfortunately the answer was disappointing: AMD was playing fast and loose with its wording. In practice, there’s still only a single rasterizer, handling a single triangle per cycle. But now there are twice as many scan conversion units, generating 32 pixels per cycle in order to match the increase in ROPs. Instead of dual rasterizers, it would be better to simply call this implementation a more powerful rasterizer.
While we’re on the subject of setup and rasterization, we should point out one other change. The fixed-function units that handled interpolation calculations have disappeared, and that job is now addressed by the shader processing units. AMD claims that the impact on performance is negligible, and this is in line with the current trend towards getting rid of as many fixed units as possible and taking advantage of the enormous processing power of modern GPUs.

As mentioned on the previous page, the organization of ATI’s stream cores hasn’t changed. They have learned to operate more efficiently, though. We established in our first look at the Radeon HD 4850 that ATI’s VLIW architecture depends on an efficient compiler in order to maximize performance—otherwise those ALUs idle. With RV770, each of the five instructions in a VLIW bundle had to be independent of the others. Now, Cypress is able to execute a multiplication and addition dependent on the outcome of the previous operation in the same cycle. Take the following example:
a=b*c;
d=a+x;
These wouldn’t have been able to share the same instruction bundle on the RV770. But here they can, since these two operations are turned into one MAD, while conserving the result of the intermediate multiplication operation. Similarly, the RV770 only had a DP4 (four-component scalar product) instruction, with the DP2 and DP3 instructions implemented using DP4. The result of that design was certain slots of the bundle were wasted on unnecessary operations. AMD says that handling of scalar products is now more flexible, though they haven't elaborated further. We suppose that the engineers have implemented DP2 and DP3 instructions natively to allow execution of other calculations in parallel.

Handling of integer operations has also been changed. Before, each of the four stream cores could execute one addition or bit shift operation on a 32-bit integer per cycle, and the special-function core could perform a multiplication or a bit shift (also on a 32-bit integer). Now the four cores are capable of performing a multiplication or addition per cycle, but only on 24-bit integers. This choice is the result of a compromise between increasing overall performance and not sacrificing too many resources to do it, as having a complete 32-bit integer multiplier in each of the stream cores would have done. By limiting themselves to 24-bit operations, the engineers can re-use resources used for handling single-precision floating-point numbers, while still maximizing utilization of the shader.
In addition to these optimizations, ATI's design team has introduced two new instructions: a fused multiply-add instruction (FMAD) which maintains the precision of the calculation throughout and performs a single final rounding, unlike a standard multiply-add (MAD), which performs two roundings. The second instruction is a sum of absolute differences (SAD), an operation frequently used in video (in particular for comparing blocks of pixels). We verified these increases in processing power using different shaders.
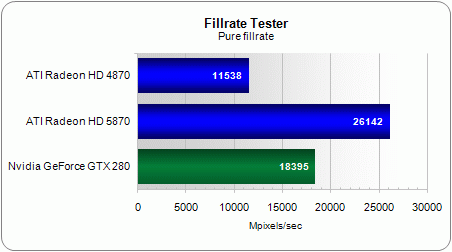
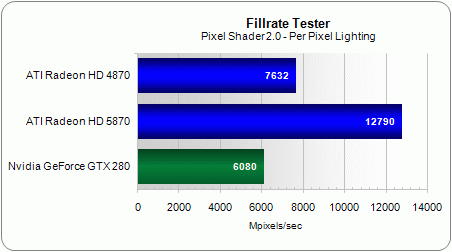
Though we’ve maintained a 2.26x gain between the Radeon HD 4870 and HD 5870 for most of the simple DirectX 9 shaders we launched, it was reduced to 1.68x when we added per-pixel lighting.
Now let’s move to more complex DirectX 10 shaders:
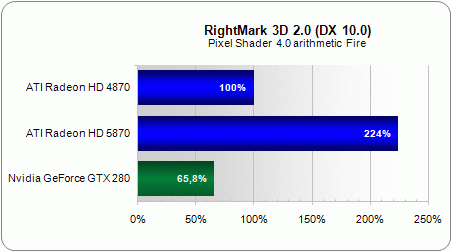
With procedural textures, the theoretical gain in raw power is almost completely realized, as the Radeon HD 5870 is 2.24x faster than the 4870. There’s no doubt that the 1,600 stream processors are present and accounted for here.
If the stream processing units haven’t changed fundamentally, the texture units have barely changed at all compared to the RV770. In practice, except for support for 16Kx16K textures and two new texture compression formats (both of which were necessary for DirectX 11 compatibility), there’s nothing new. Steep Parallax Mapping shows that fairly clearly:
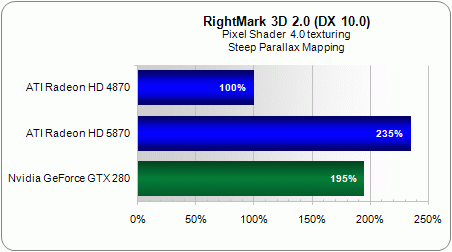
The drivers also seem to have added slight optimization, because the gain we measured here (but also with other shaders, like Fur) is as high as 2.35x between the two Radeons.
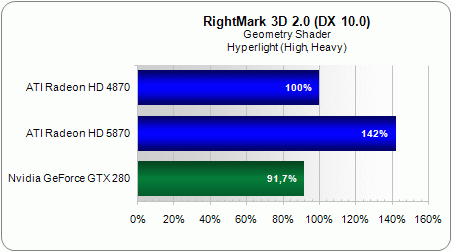
Performance with geometry shaders (geometry power), on the other hand, has improved by only 42%.
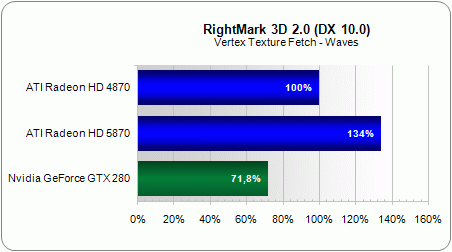
This last test measures texture fetching performance (important for displacement mapping, for example). It shows a modest improvement of 34%.
You should keep in mind that while the total bandwidth of the L1 cache has increased, it’s only by a factor of two, which is commensurate with the increase in the number of texture units. In the same way, the size of the L2 cache has doubled. But again, that's only because the number of units has also doubled. Worse, the L1/L2 bandwidth has increased only in proportion to the GPU's frequency, whereas there are now twice as many units to supply. We may have just put our finger on one reason why Cypress failed to show two times the performance of its predecessor in the preceding texture tests.
There’s not much new where the ROPs are concerned, either. AMD has simply optimized the links between the ROPs and the texture units, allowing the texture units to read the compressed format used when anti-aliasing is enabled. This feature, which Nvidia GPUs already have, should result in better performance during frame buffer post-processing operations.
Aside from that, the characteristics are exactly the same as on the RV770; maximum output with 2x and 4x (32 pixels/cycle) anti-aliasing, but reduced by half (16 pixels /cycle) when 8x antialiasing is used. There’s also been no optimization of Z-only render passes, which are still done four times as fast (128 pixels/cycle).
