





















Higher Order Surfaces, Continued
GeForce3 is able to accept control points and functions instead of triangles. Once the control points and the function are transferred to GeFroce3, it is able to create triangles out of it, which are then fed to the vertex shader. This process of making triangles out of splines is called 'tessellation'. In the past this job had to be executed by the CPU.
The advantages of higher order surfaces are clear:
- The transfer of splines instead of a large number of vertices across the AGP is able to reduce bandwidth requirements and makes AGP less of a bottleneck.
- Developers can create realistic looking objects with special tools that create the kind of higher order surfaces DirectX8 and GeForce3 understands without having to fiddle with thousands of triangles.
- 3D-objects could use only the amount of triangles they require in a certain situation, ensuring that the level of detail remains the same. This means that a car that is close in front of the scene could consist of many more triangles than the same car somewhere far behind in a corner of a 3D-scene. This mechanism is called 'adaptive tessellation'.
There is of course also a downside, even though NVIDIA's marketing papers don't talk about it:
- There are lots of different tools that can create higher order surfaces, but GeForce3 can use only certain forms.
- NVIDIA claims that collision detection is 'straightforward'. If you think again however, you will realize that a game will have a rather hard time doing collision detection if the object is not represented by actual triangles. The CPU will have to calculate the actual surface of an object each time it does the collision detection, which costs a lot of CPU horsepower.
- Finally there is the question how well GeForce3 actually performs if it has to do the tessellation. NVIDIA has not supplied an answer to this one yet.
- Not every game developer likes the idea of higher order surfaces, which e.g. require a change of the 3D-engine. John Carmack is probably the most prominent person that has reservations against it.
The idea of higher order surfaces sounds great. However, it actually sounds too good to be true. I feel as if this feature was merely implemented into GeForce3 to ensure its full DirectX8 compatibility. We will see if the performance of games with higher order surfaces will be acceptable on GeForce3. First of all we need a game that uses it.
GeForce3's Lightspeed Memory Architecture
I kept the IMHO biggest goody of GeForce3 until last. It is part of the so-called 'Lightspeed Memory Architecture' of NVIDIA's new flagship GPU and might receive a lot of attention beyond the 3D scene.
One of the most important factors for the performance of a 3D-controller is its actual memory performance, as we at Tom's Hardware guide have pointed out on numerous occasions . Typically the high fill rate claims of 3D-chip makers can never be fulfilled because the memory bandwidth required for those fill rate numbers is simply not available to the chip. This situation becomes particularly evident in 32 bit color rendering situations.
The memory bandwidth numbers listed in the specifications of graphics card are always peak performance numbers and have very little to do with the real world. People who followed the RDRAM-situation with Pentium III last year will remember that high peek bandwidth doesn't have to translate into high performance at all. Pentium III systems with the high-bandwidth RDRAM were easily beaten by other systems with PC133 memory, mainly because the latency of RDRAM is too big, making it react slowly to accesses to a different memory area than the previous addressed one.
For 3D-rendering, memory latency and granularity can become more important than peek bandwidth, because the pixel rendering is often requiring reads from memory areas that are far apart from each other. Each time a page needs to be closed and another one opened, wasting valuable time. I already discussed the fact that recently the geometric detail of scenes is increasing, leading to a growing number of triangles per frame. An increased number of triangles does automatically lead to a smaller average size of triangles as well. Detailed objects far away in the back of the scene can contain triangles that are just one pixel in size . The smaller the triangle the less effective are common memory controllers. This is for once because a new page might need to be opened just for one read/write operation. The next triangle could be just as small but in a different screen area, which would require another page open/close process that reduces the actual memory bandwidth to only a fraction of the peak bandwidth that can only be achieved with sequential reads (bursts). The second problem is the fact that common DDR-SDRAM controllers can transfer data only in 256 bit = 32 Byte chunks. If a triangle is only one pixel in size it requires a memory access of 32-Byte although only 8 Bytes (32 bit color plus 32 bit Z) are required. 75% of the memory bandwidth would be completely wasted.
GeForce3's Crossbar Memory Controller
NVIDIA decided to tackle this increasing problem in GeForce3. The task was to reduce latency and improve granularity. The result is GeForce3's brand new crossbar memory controller.
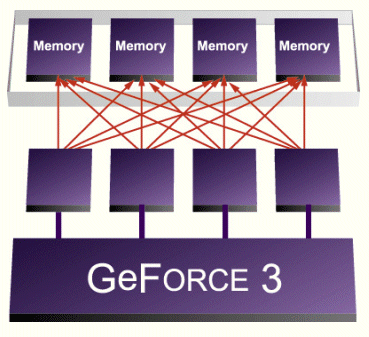
The crossbar memory controller of GeForce3 consists of four single 64 bit wide memory sub-controllers. Those sub-controllers interact with each other to address arbitration problems and make memory access as efficient as possible. The excellent design of this memory controller is able to attack both problems, latency as well as granularity. With 64 bits the granularity of each sub-controller is much finer than the 256 bit wide read/write accesses of common DDR-SDRAM controllers. The four different sub-controllers can all have open pages, which cuts the average latency down to 25%. For me personally, the memory controller is the real gem within GeForce3, because it is useful with any kind of 3D-application, regardless if brand new or ages old. Owners of GeForce3 may not be able to benefit from the vertex shader, the pixel shader or higher oder surfaces, but they will definitely be able to appreciate the crossbar memory controller. People who complain that GeForce3's theoretical peak fill rate is 'only' 800 Mpixel/s versus 1,000 Mpixel/s of GeForce2 Ultra have still not understood how it works. The high effinciency of GeForce3's memory controller will ensure that it beats GeForce2 Ultra in 99% of the cases. Regardless if the fill rate bean counters will ever understand that or not.
I wonder if companies with a really bad memory controller history, as e.g. VIA Technologies, couldn't ask NVIDIA to give them a few tips on how to implement a crossbar memory controller. There is no doubt that microprocessors could benefit from this technology as well. Rambus Inc. could use this technology to tackle the latency penalty of RDRAM. In this case I hope that NVIDIA has applied for a patent early enough, because otherwise Rambus may follow its tradition, copy NVIDIA's design, patent it and then sue NVIDIA. But jokes aside, NVIDIA is known to work on a core logic (=chipset) anyway and, who knows, the crossbar memory controller might soon enough find its way on motherboards with NVIDIA chipsets. Intel, and VIA beware!
GeForce3's Approach To Tackle The Z-Buffer - HyperZ Made In Sunnyvale
The second part of GeForce3's 'Lightspeed Memory Architecture' is an implementation to reduce Z-buffer reads. I have described the high impact of z-buffer reads and the waste of fill rate as well as memory bandwidth for hidden pixels or triangles in my article about ATi's Radeon256 already. Please have a look at this page if you should not be familiar with the problem.
NVIDIA has finally seen the same signs that made ATi design their HyperZ-technology and now GeForce3 receives a similar feature set as already found in ATi's Radeon256.
The frame buffer area that is most accessed by a 3D-chip is the z-buffer. The reason is fairly simple. There are only few memory accesses up to the triangle setup and rasterizer stage of the 3D-pipeline. The rasterizer stage is also defining the 'birth' of the z-buffer. All previous stages are handling vertices, which carry their z-coordinate along with them. The triangle setup/rasterizer calculates the color values, the texture coordinates and the z-value for each pixel of a triangle and sends it to the rendering pipeline.
The first thing the pixel render engine (in GeForce3's case the 'Pixel Shader') does after it received a new pixel is read the z-buffer. This stage is required because the pixel render engine needs to know if there is already another pixel at the x/y-coordinate of the new pixel and if this 'older' pixel is actually lying in front of it. If the z-value at this coordinate is zero or less than the z-value of the new pixel, it goes through the pixel-rendering engine. When the pixel is ready rendered the color value is written to the back buffer and the z-value of this pixel is stored in the z-buffer. Now the next pixel is fetched from the rasterizer and the game begins anew. You can see that per triangle-pixel the z-buffer is accessed at least once for a read operation and per displayed pixel the z-buffer is accessed once more. No other buffer gets hit that often. You can imagine that a reduction of z-buffer accesses could save highly valuable memory bandwidth.
Lossless Z Compression
The first way that NVIDIA uses to reduce the amount of required z-buffer bandwidth is to implement a (thankfully) lossless compression of the z-buffer. ATi's Radeon256 is doing the same since July 2000. NVIDIA speaks of a lossless 4:1 compression, which could theoretically reduce the impact of z-buffer accesses on the memory bandwidth by already 75%. Lossless 4:1 compression is not as simple however. Try it by yourself. Create a text file with 'hello world' and zip it. Zip/unzip is also a lossless compression of files. You will see that the compression rate increases as the size of the text file increases. This goes only up to a certain level, but it is a fact that a text file that only contains the letter 'h' will certainly not get a high compression ratio. The same is valid for the z-buffer compression of GeForce3 and Radeon256. Neither of the two will read or write the whole z-buffer when one address is accessed, but one z-buffer value alone can obviously not be compressed 4:1 as well. It is most likely that GeForce3 is compressing sub-units of the z-buffer that are cached on the GeForce3 chip. Radeon256 is using 8x8 = 64 Byte sub units.
Visibility Subsystem: Z Occlusion Culling
What's hidden behind this fancy name is NVIDIA's version of Radeon's Hierarchical-Z plus advancement. The Z occlusion Culling is special procedure between the stages of the triangle setup/rasterizer and the Pixel Shaders to determine if a pixel will be hidden behind an earlier rendered pixel or not. If the Z occlusion culling should determine that the pixel is hidden it will directly be discarded and it won't enter the pixel shader, thus saving the initial z-buffer read of the pixel-rendering pipeline.
The technology behind this process is most likely, just as in Radeon's case, a hierarchical Z-cache that covers a certain part of the screen. This cache can quickly read one of the above-mentioned 4:1 compressed sub-units of the z-buffer and probably represent the z-buffer in blocks of pixels, simply storing the lowest z-value found in this block. When the triangle setup/rasterizer is spitting out a pixel, the z occlusion culling will compare its z-value with the value stored for the according pixel block. If the z-value of the pixel is clearly lower than the z-value of the pixel block representation, the pixel will be discarded. If the z-value is larger than the block value it will be sent to the pixel shader.
NVIDIA's advance over ATi's Hierarchical-Z is what they call 'Occlusion Query'. The 3D-application requests GeForce3 to check the z-values of a special area (which will most certainly be of the same size as the hierarchical z-cache). If it turns out that the triangles in this area are hidden behind an object that has already been rendered all triangles of that area will be discarded.
It has to be said that the efficiency of this z occlusion culling or hierarchical-z method is depending on the 3D-application. The best effects can be seen if the 3D-application is sorting its scene objects before it sends them one by one to the 3D-chip. The ideal case is if the application is first sending the objects in the front of the scene and then the objects further behind. It avoids that pixels of hidden objects in the background of the scene are rendered first and later overwritten by pixels of objects in front of them. The worst case would be if the application would sort the objects back-to-front (which no application would deliberately do). Then even Z Occlusion Culling or Hierarchical-Z couldn't help a bit. In average the 3D-objects are drawn in random succession, leading to a depth complexity of 2 - 3.5. In this case GeForce3's Z Occlusion Culling can be of great use.
Conclusion
Could there possibly be a conclusion without any hard benchmark data? Not in case of a high-end 3D-chip. However, I can certainly offer a summary and a personal opinion about GeForce3's technology.
First of all I would like to say that this article is not just incidentally the longest article I have ever written. If you take in consideration that it doesn't even include one benchmark graph, you will get an idea how huge this article really is. The amount of technology provided by NVIDIA's new GeForce3, the Xbox predecessor chip, is simply overwhelming. This processor doesn't 'just' have 57 million transistors. They have actually been USED! If it is the Vertex Shader, the Pixel Shader, the High Resolution Anti Aliasing, the Crossbar Memory Controller or the Z Occlusion Culling, this chip has been STUFFED with high-tech! Let me now take a deep breath and go through the new technologies one by one.
Vertex Shader
I have to say that I love this feature, because it offers a tremendous amount of possibilities. My personal favorite is the reflection and refraction demo, which really shows how close 3D rendering can get to reality. However (with Tom there's always a 'however!'), it remains to be seen if the single vertex shader pipeline of GeForce3 will be performing well enough to make games with all those great features playable and not just eye candy. Right now, the maximal amount of vertex instructions is limited to 128 and although the vertex shader is strictly scalar, NVIDIA has decided to supply GeForce3 with only a single pipeline. Xbox will most likely have two pipelines. I can't say it often enough, I hope that the vertex shader will perform well enough.
Pixel Shader
This unit seems to be a straightforward development of previous pixel rendering units. I don't know if the programmability of it will be good enough to set it far apart from previous pixel renderers. The most important feature of the pixel shader is that the vertex shader drives it. From that point of view it makes perfect sense. One couldn't live without the other. I am less concerned about the rendering performance of the pixel shader, even though the theoretical peak fill rate is less than that of GeForce2 Ultra. The new memory controller will make sure that GeForce3 will beat GeForce2 Ultra by quite a long shot.
High Resolution Anti Aliasing
This feature - excuse me - kicks ass! I have tested it numerous times here and it works, performs well and looks great. I never used to be a big fan of anti aliasing so far, even though my usual system is equipped with a GeForce2 Ultra. The performance with anti-aliasing enabled was too poor that the effect would have been worth it. With GeForce3 anti-aliasing has become reality. 1024x768x32 with Quincunx-AA enabled at more than 70 fps is more than satisfying and looks excellent. I only wonder if NVIDIA shouldn't have changed the name of 'Quincunx'. The Internet will soon rename it to something else.