





















SCINet Network Operations Center At SuperComputing 2017

The network infrastructure required to run a massive tradeshow may not seem that exciting, but Supercomputing 17's SCinet network is an exception. This massive collection of eight racks consisted of $66 million in hardware and software from 31 contributors. The network provided 3.63 Tb/s of WAN bandwidth to multiple locations all around the world. It required 60 miles of fiber, 2,570 fiber patches, and 280 wireless access points. The final SCinet network was the culmination of a year of planning and two weeks of assembly with 180 volunteers. Tearing down is easier than building up, so the volunteers were able to disassemble the entire network in one day.
The Stratix 10 Development Board

Intel announced its Stratix 10 FPGAs back in October 2016. The new FPGA comes with a quad-core ARM Cortex-A53 processor, though we imagine that will be swapped out with Intel cores in future models. The card also has the option for embedded HBM2 in the package.
We spotted a development board at the Reflex CES booth. Reflex CES designs custom embedded solutions and is working on a Stratix 10 GX/SX design that features three onboard DDR4 banks. It currently has three models shipping.
The beefier Intel Stratix 10 MX models come with HBM2 in the package, so Intel can mix and match components. That's a key advantage of Intel's new EMIB (Embedded Multi-Die Interconnect Bridge). This technology (deep dive here) made its debut on the Stratix 10 line of FPGAs and also serves as one of the key technologies enabling Intel's surprising use of AMD's graphics on its next-gen H-Series mobile processors.
The development board obviously requires quite a bit of cooling, but that's the result of the passive heatsink on the device. Like most server components, the high rate of linear airflow inside of a server will keep it comfortably within its normal operating temperature.
Intel's Arria 10 Solution

Speaking of Intel's FPGA's, the company announced last month that it would bring its Programmable Acceleration Card to market with the Arria 10 GX FPGA. The company had the card displayed in its booth, but it will eventually make its way into OEM systems from Dell EMC, among others. The company said the card will become available in the first half of 2018.
The Arria 10 FPGA features 1.15 million logic elements. The card connects to the host via a PCIe 3.0 x8 connection and comes with 8GB of onboard DDR4 memory and an undisclosed amount of flash storage. It also features an integrated 40Gb/s "capable" QSFP+ interface for networking.
Xilinx FPGA And EPYC Server


Xilinx had several demos of FPGA-enabled workloads and systems in action. Of course, the single-socket EPYC server paired with four VU9P Virtex UltraScale+ FPGAs caught our eye. This system serves as a perfect example of the capabilities borne of EPYC's burly PCIe connectivity. Memory capacity and performance is also a limiting factor for many workloads, so EPYC's 145GB/s of bandwidth, eight DDR4 channels, and 2TB of memory capacity for a single socket server is a good fit for many diverse workloads.
We took a deeper look at the system in our "Xilinx Pairs AMD's EPYC With Four FPGAs" article.
Xilinx Facial Detection Demo

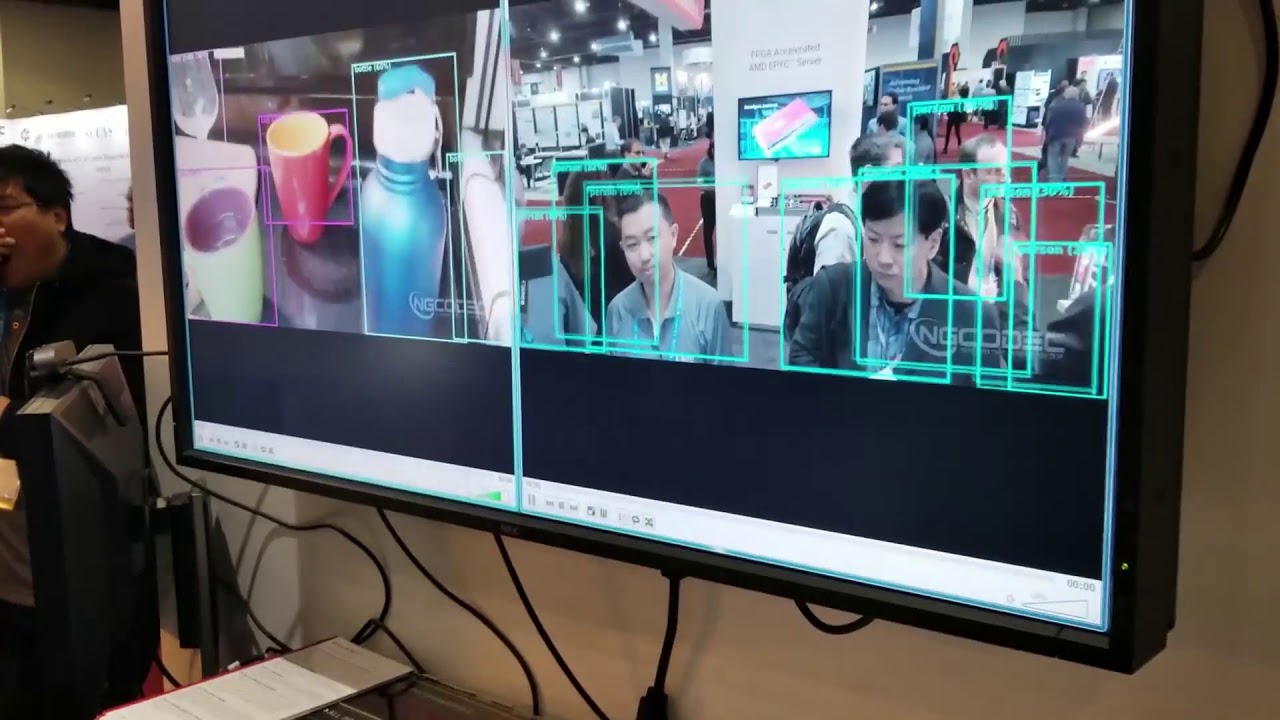
AI workloads are spreading out to the edge for many purposes, such as facial detection and encoding in surveillance systems. Xilinx had an interesting demo that showed a working system in action.
The Mini Data Center

If there's one thing we love, it's mini systems. Packing a ton of compute in a small space is the ultimate goal for all forms of computing, so the DOME hot water-cooled microDataCenter stood out from the pack.
The joint IBM/DOME project has created a series of hot-swappable cards that serve many purposes. You can pick from ARM Cortex-A72, Kintex-7 FPGAs, PowerPC-64, Xeon-Ds, or Xavier GPU cards (several pictured at the front of the display) to mix-and-match compute capabilities in a truly miniature data center (the mouse in the upper right serves as a good sense of scale). Here we see 32 cards crunching away with various processors. There are also dedicated NVMe storage cards available, but networking is built into the host PCB.
Water and power flow through both sides of the enclosure. The group claimed that two of these mini racks, which drop into a standard 2U server rack, can offer as much performance as 64 2U nodes. The result? 50% less energy consumption in 90% less space. We've grossly oversimplified the project, but look to these pages for more coverage soon.
The 750-Node Raspberry Pi Cluster

The Los Alamos National Laboratory's HPC Division has deployed 750-node Raspberry Pi clusters for development purposes. The lab is using five racks of BitScope Cluster modules, with 150 Raspberry Pi units each, to build a massively parallel cluster featuring 750 four-core processors for a total of 3,000 cores. The ARM-based system sips a mere 4,000W under full load. Unfortunately, the company did not have a working demo of its cluster at the show, but we've got a much smaller Raspberry Pi cluster demonstration on the following page.
University of Edinburgh Homemade Raspberry Pi Cluster

The University of Edinburgh's homemade Raspberry Pi cluster isn't as expansive as the 3,000-core behemoth on the preceding slide, but it serves as a good illustration of how 18 low-power (not to mention cheap) Raspberry Pis can exploit parallel computing to perform complex operations, in this case designing and testing an aircraft wing.
The university built the Wee Archie Raspberry Pi cluster to teach the basics of supercomputing and open sourced the design here.
Nvidia DGX-1

Nvidia's DXG-1 systems, which we've covered several times, are available to the public, but Jensen Huang is also using them as a building block to update the company's SaturnV supercomputer. The company claimed it should land within the top ten on the Top500 supercomputer list, and perhaps even break into the top 5.
The SaturnV supercomputer will be powered by 660 Nvidia DGX-1 nodes (more detail on the nodes here), spread over five rows. Each node houses eight Tesla V100s for a total of 5,280 GPUs. That powers up to 660 PetaFLOPS of FP16 performance and a peak of 40 PetaFLOPS of FP64. The company plans to use SaturnV for its own autonomous vehicle development programs.
Nvidia Workstation

And finally, Nvidia's DGX Station. This good-looking box comes with four watercooled Tesla V100s and can churn out 480 TeraFLOPS of performance (FP16). The system features 64GB of GPU memory and a total of 20,480 CUDA cores. Throwing in 256 GB of DDR4 memory and three 1.92TB SSDs in RAID 0 sweetens the deal, but only for those brave-hearted folks who actually trust RAID 0 to store anything. In either case, Nvidia includes a 1.92TB SSD for the operating system and a dual 10Gb LAN networking solution rounds out the system.
Your power bill might shoot up--the system consumes 1,500W under full load--but it won't seem as bad after you pay $69,000 for this stunner.
