
Data center GPUs from Nvidia have become the gold standard for AI training and inference due to their high performance, the use of HBM with extreme bandwidth, fast rack-scale interconnects, and a perfected CUDA software stack. However, as AI becomes more ubiquitous and models are becoming larger (especially at hyperscalers), it makes sense for Nvidia to disaggregate its inference stack and use specialized GPUs to accelerate the context phase of inference, a phase where the model must process millions of input tokens simultaneously to produce the initial output without using expensive and power-hungry GPUs with HBM memory. This month, the company announced its approach to solving that problem with its Rubin CPX— Content Phase aXcelerator — that will sit next to Rubin GPUs and Vera CPUs to accelerate specific workloads.
The shift to GDDR7 provides several benefits, despite delivering significantly lower bandwidth than HBM3E or HBM4; it consumes less power, costs dramatically less per GB, and does not require expensive advanced packaging technology, such as CoWoS, which should ultimately reduce the product's costs and alleviate production bottlenecks.

What is long-context inference?
Modern large language models (such as GPT-5, Gemini 2, and Grok 3) are larger, more capable in reasoning, and able to process inputs that were previously impossible, which end-users utilize extensively. The models are not only larger in size, they are also architecturally more capable of using extended context windows effectively. Inference in large-scale AI models is increasingly divided into two parts: an initial compute-intensive context phase that processes the input to generate the first output token, and a second phase that generates additional tokens based on the processed context.
As models evolve into agentic systems, long-context inference becomes essential for enabling step-by-step reasoning, persistent memory across tasks, coherent multi-turn dialogue, and the ability to plan and revise over extended inputs, as otherwise these capabilities would be limited by context windows. Perhaps the most important factor why long-context inference becomes important is not just because models can do it, but because users need AI to analyze large documents, codebases, or generate long videos.
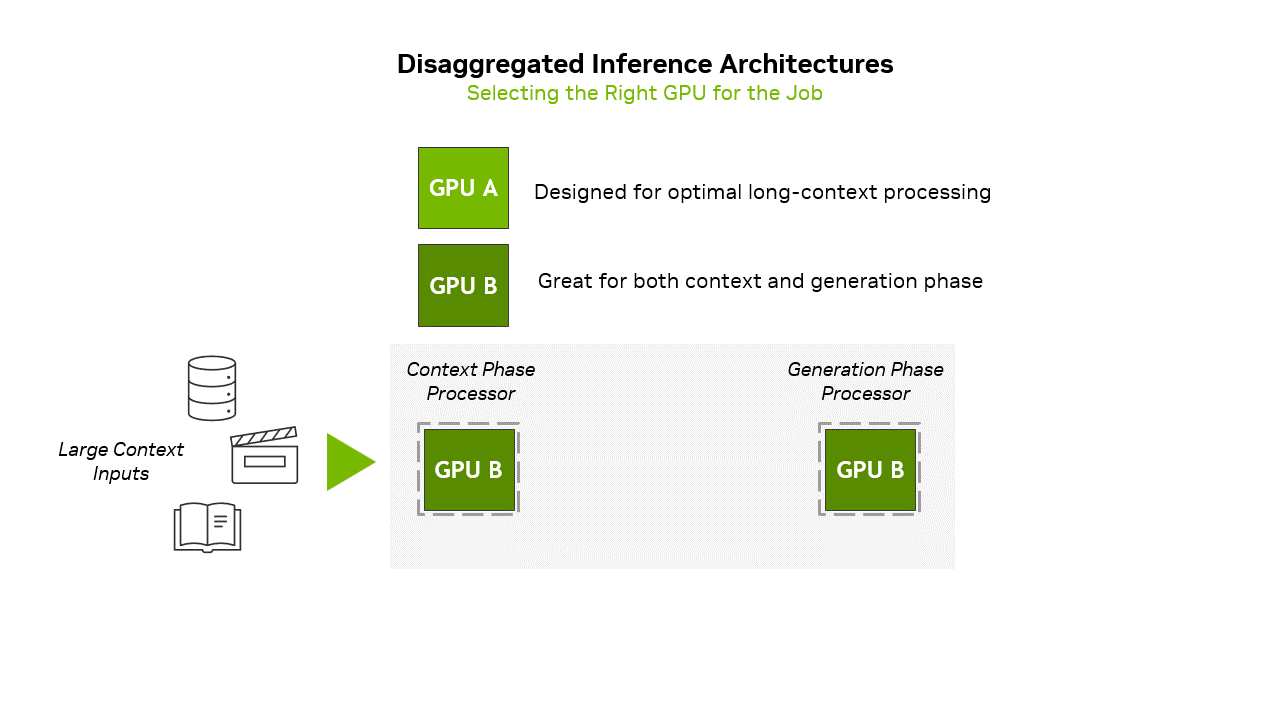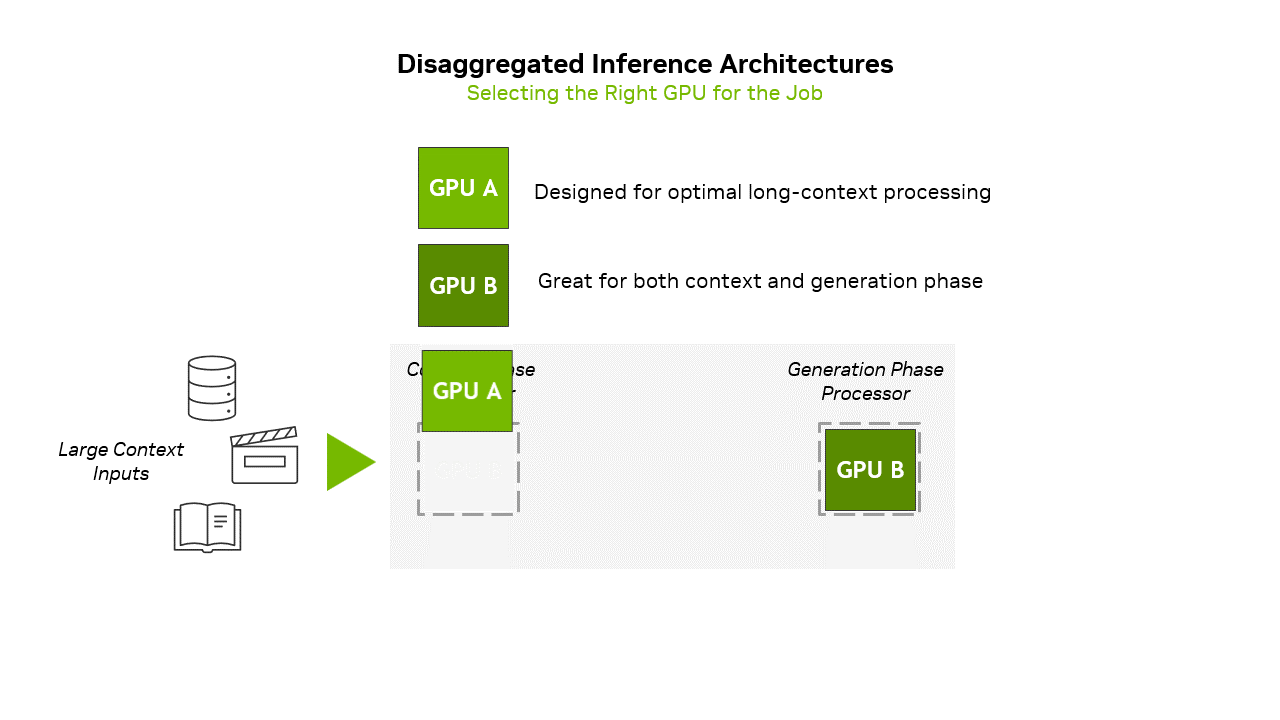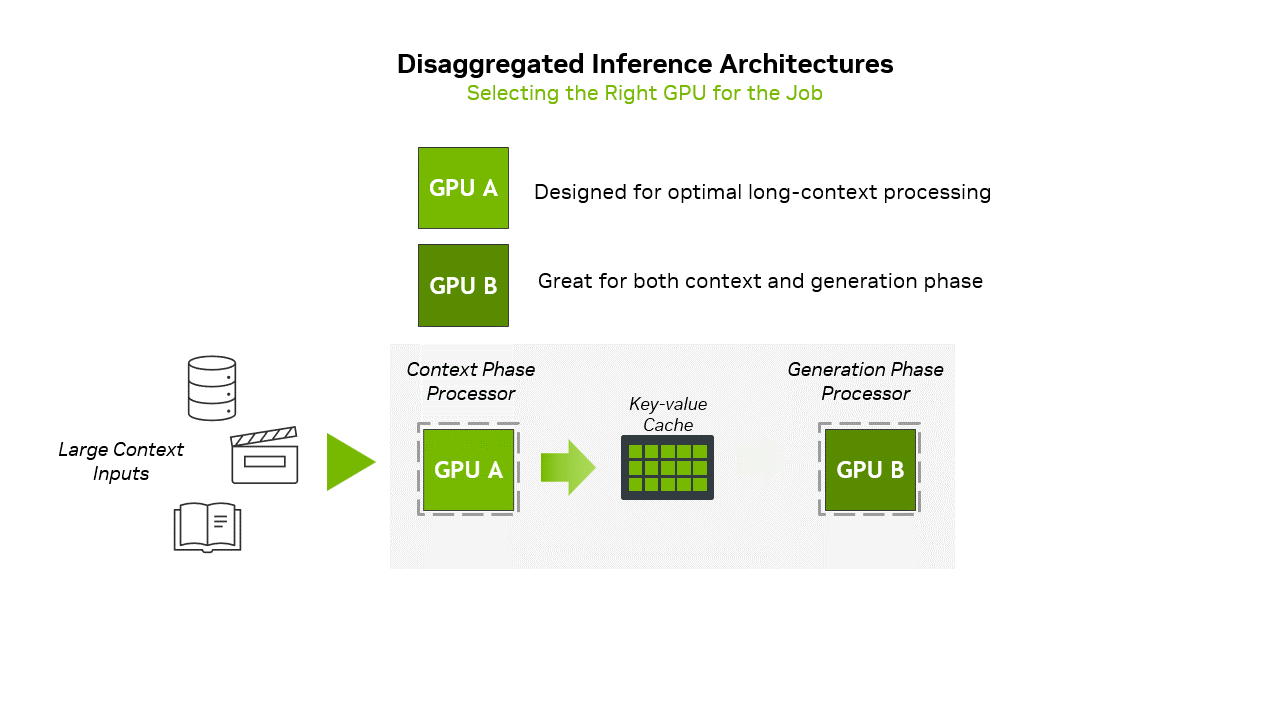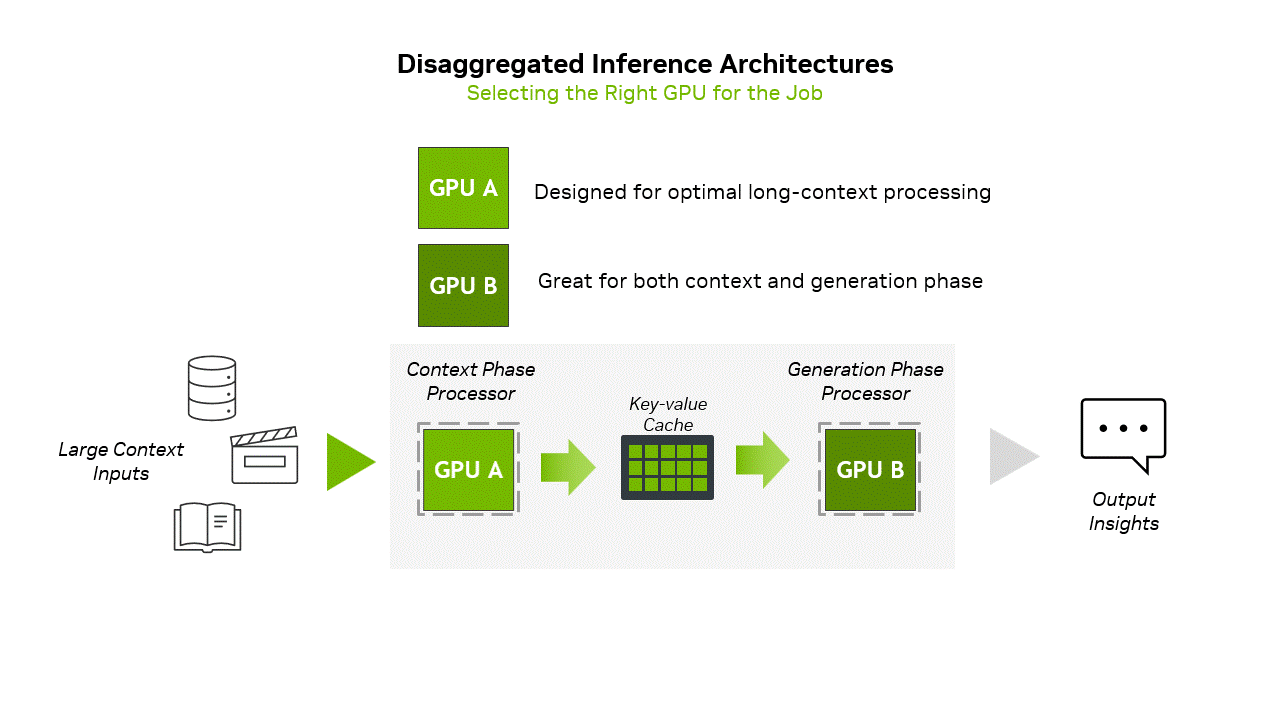
This type of inference presents distinct challenges to hardware. The context phase of inference — where the model reads and encodes the full input before producing any output — is compute-bound and requires extremely high compute throughput to produce 1+ million token context workloads, plenty of memory (but not necessarily plenty of memory bandwidth), and optimized attention mechanisms (which is the model developers' job) to maintain performance across long sequences. Traditional data center GPUs have plenty of onboard HBM memory, and while they can handle such workloads, it is not very efficient to use it for this task. Therefore, Nvidia intends to use Rubin CPX GPUs with 128GB of GDDR7 onboard for the context phase.
During the second phase, the model generates output tokens one at a time using the encoded context from the first phase. This step is memory bandwidth and interconnect-bound, requiring fast access to previously generated tokens and attention caches. Traditional data center GPUs — such as the Blackwell Ultra (B300, 288GB HBM3E) or Rubin (288GB HBM4) — handle this efficiently by streaming and updating token sequences in real-time.
Meet Rubin CPX
To address emerging demands, Nvidia has designed specialized hardware — the Rubin CPX GPU — specifically for long-context inference.
The Rubin CPX accelerator card is built on Nvidia's Rubin architecture, delivering up to 30 NVFP4 PetaFLOPS of compute throughput (which is quite a lot, as the 'big' Rubin R100, featuring two chiplets, achieves 50 NVFP4 PetaFLOPS), and it comes with 128GB of GDDR7 memory. The processor also has hardware attention acceleration (which involves additional matrix multiplication hardware), which is crucial for long-context inference without speed drops, as well as hardware support for video encoding and decoding for processing and generating videos.
The use of GDDR7 is one of the key distinctive features of the Rubin CPX GPU. While GDDR7 provides significantly lower bandwidth than HBM3E or HBM4, it consumes less power, costs dramatically less per GB, and does not require expensive advanced packaging technology, such as CoWoS. As a result, not only are Rubin CPX GPUs cheaper than regular Rubin processors, but they also consume significantly less power, which simplifies cooling.

A quick look at Nvidia's die shot of the Rubin CPX GPU indicates that its floorplan resembles that of high-end graphics processors (to a degree that even its heatspreader resembles that of GB202). The ASIC indeed has 16 graphics processing clusters (GPCs,) allegedly with graphics-specific hardware (e.g., raster back end, texture units), a massive L2 cache, eight 64-bit memory interfaces, PCIe, and display engines. What the chip does not seem to have are interfaces like NVLink, so we can only wonder whether it communicates with its peers only via a PCIe interface.
We can only wonder whether the Rubin CPX uses the GR102/GR202 graphics processor (which will power next-generation graphics cards both for consumers and professionals) or if the unit uses a unique ASIC. On the one hand, using a client-grade GPU for AI inference acceleration is not a new concept: the GB202 offers 4 NVFP4 PetaFLOPS, whereas the GB200 features 10 NVFP4 PetaFLOPS. On the one hand, packing plenty of NVFP4-capable FPUs and hardware attention accelerators into a GPU for graphics may not be the most optimal choice from a die size perspective. But on the other hand, taping out two near-reticle-size processors with similar functionality instead of one could be inefficient from a cost, engineering effort, and timing perspective.
Rubin CPX will operate alongside Rubin GPUs and Vera CPUs in the Vera Rubin NVL144 CPX system, which delivers 8 ExaFLOPS of NVFP4 performance (3.6 ExaFLOPS using 'Big' Rubin GPU and 4.4 ExaFLOPS using Rubin CPX GPUs) and 100TB of memory in a single rack. Just like other rack-scale products from Nvidia, the Vera Rubin NVL144 CPX will utilize Nvidia's Quantum-X800 InfiniBand or Spectrum-XGS Ethernet connectivity, paired with ConnectX-9 SuperNICs, for scale-out connectivity.
Nvidia said that its Rubin CPX architecture is not limited to Vera Rubin NVL144 CPX full-rack installations. The company intends to offer Rubin CPX compute trays for integration into Vera Rubin NVL144 systems. However, it appears that existing Blackwell deployments will not be able to accommodate Rubin CPX trays for optimized inference performance, although the reason for this is unclear.
Regardless of deployment scale, Rubin CPX is intended to provide noticeable economic benefits, according to Nvidia. A $100 million investment in this platform can potentially yield up to $5 billion in revenue from token-based AI applications, translating to a 30- to 50-times return on capital invested, the company claims. This claim is grounded in the ability of Rubin CPX to reduce inference costs (as Rubin CPX is cheaper and consumes less than full-blown R100) and expand the scope of feasible AI workloads.
No need to redesign software
On the software side, Rubin CPX is fully supported by Nvidia's AI ecosystem, including CUDA, frameworks, tools, and NIM microservices required for deploying production-grade AI solutions. Rubin CPX also supports the Nemotron family of models, designed for enterprise-level multimodal reasoning.

Developers of AI models and products will not need to manually partition the first and second inference phases between GPUs to run on Rubin NVL144 CPX rack-scale solutions. Instead, Nvidia proposes using its Dynamo software orchestration layer to intelligently manage and split inference workloads across different types of GPUs in a disaggregated system. When a prompt is received, Dynamo automatically identifies the compute-heavy context phase and assigns it to specialized Rubin CPX GPUs, which are optimized for fast attention and large-scale input processing. Once the context is encoded, Dynamo seamlessly transitions to the generation phase, routing it to memory-rich GPUs like the standard Rubin, which are better suited for token-by-token output generation. Nvidia says that Dynamo can manage KV cache transfers as well as minimize latency.
Clients lining up
Several companies are already planning to integrate Rubin CPX into their AI workflows:
- Cursor, a software company that develops AI for software developers, will use Rubin CPX to support real-time code generation and collaborative development tools.
- Runway plans to use Nvidia Rubin CPX to power long-context, agent-driven video generation, enabling creators — from solo artists to major studios — to produce cinematic content and visual effects with greater speed, realism, and creative flexibility.
- Magic, an AI research company developing autonomous coding agents, plans to use Rubin CPX to support models with 100 million-token context windows, enabling them to operate with full access to documentation, code history, and user interactions in real-time.
A new paradigm
Ever since Pascal and Volta GPUs about a decade ago, Nvidia's GPUs were AI accelerators for CPUs. With Rubin CPX, these GPUs now get their own accelerators. By decoupling two stages of inference — context processing and token generation — Nvidia enables more targeted use of hardware resources, improving efficiency at scale, which represents a shift of how AI infrastructure is being optimized for maximum efficiency.
Optimization of long-context inference processing not only cuts hardware costs and TCO, but also enables high-throughput inference platforms capable of sustaining million-token workloads. Such platforms could enable even more sophisticated AI-assisted software and hardware engineering, as well as full-length video generation and other AI applications that are not feasible today.
Nvidia's first Rubin CPX-enabled platform, the Vera Rubin NVL144 CPX, is expected to be available by the end of 2026.
Follow Tom's Hardware on Google News, or add us as a preferred source, to get our up-to-date news, analysis, and reviews in your feeds. Make sure to click the Follow button!
