
Nvidia's Ada architecture and GeForce RTX 40-series graphics cards first started shipping on October 12, 2022, starting with the GeForce RTX 4090. The GeForce RTX 4080 followed one month later on November 16, 2022, then the RTX 4070 Ti (formerly RTX 4080 12GB) launched on January 5, 2023, and the RTX 4070 on April 13. Those are all basically two years after the Nvidia Ampere architecture and basically right on schedule given the slowing down (or if you prefer, death) of Moore's 'Law.' Now, with the launch of the 40-series Super mid-cycle refresh, Nvidia has seemingly wrapped up the current offerings that compete with the best graphics cards.
With the Nvidia hack early in 2022, we had a good amount of information on what to expect. All the cards are now shipping and we have tested and reviewed every model of the Nvidia RTX 40-series. We've collected everything into this central hub detailing everything we know about Nvidia's Ada architecture and the RTX 40-series family.
The one remaining "unknown" is whether the rumored Titan RTX Ada / RTX 4090 Ti will ever appear, and if Nvidia might attempt to create an RTX 4050 — most likely no on both, but never say never. Just look at the RTX 3050 6GB, which came years after the 30-series first launched. But outside of those two potential exceptions, we now have basically everything there is to know about the Ada Lovelace architecture.
With the Ada whitepaper now available alongside the GPUs, we've updated the information here to cover exactly what the new generation of GPUs delivers. Let's start with the high level overview of the specs and rumored specs for the Ada series of GPUs.
GeForce RTX 40-Series Specifications
| Graphics Card | RTX 4090 | RTX 4080 Super | RTX 4080 | RTX 4070 Ti Super | RTX 4070 Ti | RTX 4070 Super | RTX 4070 | RTX 4060 Ti 16GB | RTX 4060 Ti | RTX 4060 |
|---|---|---|---|---|---|---|---|---|---|---|
| Architecture | AD102 | AD103 | AD103 | AD103 | AD104 | AD104 | AD104 | AD106 | AD106 | AD107 |
| Process Technology | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N | TSMC 4N |
| Transistors (Billion) | 76.3 | 45.9 | 45.9 | 45.9 | 35.8 | 32 | 32 | 22.9 | 22.9 | 18.9 |
| Die size (mm^2) | 608.4 | 378.6 | 378.6 | 378.6 | 294.5 | 294.5 | 294.5 | 187.8 | 187.8 | 158.7 |
| SMs / CUs / Xe-Cores | 128 | 80 | 76 | 66 | 60 | 56 | 46 | 34 | 34 | 24 |
| GPU Cores (Shaders) | 16384 | 10240 | 9728 | 8448 | 7680 | 7168 | 5888 | 4352 | 4352 | 3072 |
| Tensor / AI Cores | 512 | 320 | 304 | 264 | 240 | 224 | 184 | 136 | 136 | 96 |
| Ray Tracing Cores | 128 | 80 | 76 | 66 | 60 | 56 | 46 | 34 | 34 | 24 |
| Boost Clock (MHz) | 2520 | 2550 | 2505 | 2610 | 2610 | 2475 | 2475 | 2535 | 2535 | 2460 |
| VRAM Speed (Gbps) | 21 | 23 | 22.4 | 21 | 21 | 21 | 21 | 18 | 18 | 17 |
| VRAM (GB) | 24 | 16 | 16 | 16 | 12 | 12 | 12 | 16 | 8 | 8 |
| VRAM Bus Width | 384 | 256 | 256 | 256 | 192 | 192 | 192 | 128 | 128 | 128 |
| L2 / Infinity Cache | 72 | 64 | 64 | 64 | 48 | 48 | 36 | 32 | 32 | 24 |
| Render Output Units | 176 | 112 | 112 | 96 | 80 | 80 | 64 | 48 | 48 | 48 |
| Texture Mapping Units | 512 | 320 | 304 | 264 | 240 | 224 | 184 | 136 | 136 | 96 |
| TFLOPS FP32 (Boost) | 82.6 | 52.2 | 48.7 | 44.1 | 40.1 | 35.5 | 29.1 | 22.1 | 22.1 | 15.1 |
| TFLOPS FP16 (FP8) | 661 (1321) | 418 (836) | 390 (780) | 353 (706) | 321 (641) | 284 (568) | 233 (466) | 177 (353) | 177 (353) | 121 (242) |
| Bandwidth (GBps) | 1008 | 736 | 717 | 672 | 504 | 504 | 504 | 288 | 288 | 272 |
| TDP (watts) | 450 | 320 | 320 | 285 | 285 | 220 | 200 | 160 | 160 | 115 |
| Launch Date | Oct 2022 | Jan 2024 | Nov 2022 | Jan 2024 | Jan 2023 | Jan 2024 | Apr 2023 | Jul 2023 | May 2023 | Jul 2023 |
| Launch Price | $1,599 | $999 | $1,199 | $799 | $799 | $599 | $599 | $499 | $399 | $299 |
| Online Price | $2,000 | $1,000 | $1,160 | $800 | $742 | $600 | $535 | $440 | $385 | $295 |
With the RTX 4080 Super, RTX 4070 Ti Super, and RTX 4070 Super functioning as the mid-cycle refresh, it seems Nvidia has wrapped up the 40-series consumer parts. There are eleven desktop variants in total, plus another five laptop parts and various data center and professional GPUs as well (which we don't list in the above table).
There isn't a desktop RTX 4050, unless that changes down the road, and no top-end 4090 Super refresh or new Titan card. The latter isn't too surprising, considering the demand from the AI sector for AD102-based GPUs. Nvidia would rather sell data center parts at higher prices than to offer a new consumer part — particularly when AMD doesn't have anything that can match the 4090.
Nvidia has five different Ada Lovelace GPUs, one more than the previous Ampere architecture. RTX 4090 uses a significantly trimmed down AD102 implementation (89% of the cores, 75% of the cache). Meanwhile, RTX 4080 uses an "almost complete" AD103 chip (95% of the cores and all the cache), the RTX 4080 Super uses the full AD103, and RTX 4070 Ti Super uses a significantly cut back chip (83% of the cores). RTX 4070 Ti also uses a fully enabled AD104 chip, RTX 4070 uses 77% of the chip, and RTX 4070 Super lands between the two with 93% of the chip. Then the RTX 4060 Ti uses most of an AD106 (94%), while the RTX 4060 uses the whole AD107 chip.
Nvidia "went big" with the AD102 GPU, and it's closer in size and transistor counts to the H100 than GA102 was to GA100. Frankly, it's a monster, with performance and price to match. It packs in far more SMs and the associated cores than any Ampere GPUs, it has much higher GPU clocks, and it also contains a number of architectural enhancements to further boost performance. Nvidia claimed that the RTX 4090 is 2x–4x faster than the outgoing RTX 3090 Ti, though caveats apply to those benchmarks.
Our own testing puts performance at more like 60% faster in aggregate compared to the previous generation RTX 3090 Ti. That's at 4K and maxed out settings, without DLSS 2 or DLSS 3. But as we noted in our reviews, while DLSS 3 Frame Generation can boost frame rates, it's not the same as "real" frames and it typically adds latency, meaning it feels more like a 10–20 percent improvement over the baseline performance, at best. It's also worth noting that if you're currently running a more modest processor rather than one of the absolute best CPUs for gaming, you could very well end up CPU limited even at 1440p ultra with the 4090. A larger system upgrade will likely be necessary to get the most out of the fastest Ada GPUs.
Nvidia is hitting clock speeds of 2.5–2.6 GHz on all the RTX 40-series GPUs. That's actually the conservative side of things. In practice, our testing shows every 40-series part running at 2.6–2.8 GHz in gaming workloads. It's a big jump from the sub-2.0 GHz clocks we've seen from Nvidia for the past several generations.
The memory didn't get much of a boost in clocks or bandwidth, with most models sticking with GDDR6X clocked at 21–23 Gbps. The 3090 Ti also used 21 Gbps GDDR6X, so only the 4080 and 4080 Super got faster memory speeds. Nvidia makes up for the lack of bandwidth improvements by adding a significantly large chunk of L2 cache — 6MB or 8MB per 32-bit interface, compared to 1MB per 32-bit interface on Ampere — more on this below.
TSMC 4n: "4nm Nvidia"
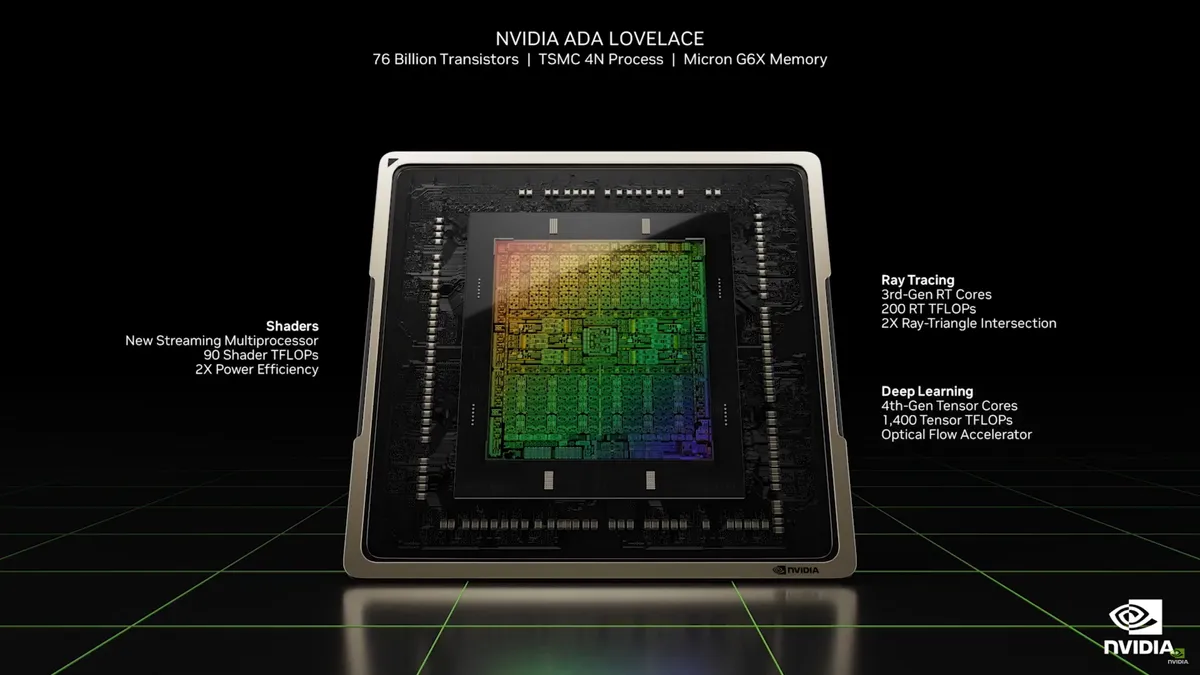
Nvidia uses TSMC's 4N process — "4nm Nvidia" — on all the Ada and Hopper GPUs, from the big AD102 and H100 down to the smallest AD107. TSMC's 4N node is a tweaked and refined variation on TSMC's N5 node that's been widely used in other chips, and which is also used for AMD's Zen 4 and RDNA 3. Samsung doesn't currently have a compelling alternative that wouldn't require a serious redesign of the core architecture, so the whole family will be on the same node.
TSMC N4 offers several major improvements over the Samsung 8N ("8nm Nvidia") used on Ampere. Specifically, it has much smaller features, meaning Nvidia can pack in a lot more transistors in a similar or smaller area. AD102 for example has 76.3 billion transistors in a 608mm^2 die size, or on average roughly 125 million transistors per square millimeter (MTrans/mm^2). AD103/106/107 offer a similar 119~121 density, while AD104 is the least-dense chip with "only" 109 MTrans/mm^2. The Ampere GA102/104/106 GPUs by comparison packed around 43~45 MTrans/mm^2.
The N4 process node also allows for lower power use and improved efficiency. Yes, the RTX 4090 has a massive 450W TGP (total graphics power) budget, but across a 15 game test suite, it averaged 390W at 4K ultra settings in our testing. The most demanding games could pull 450W, while others only needed around 300~325 watts. And that's the worst example from Ada; the RTX 4080, 4070 Ti, and 4070 are all at the top of our efficiency metric, in terms of FPS per watt.
Finally, as noted above, clock speeds are much higher with Ada than with Ampere. Official clocks have increased from 1,665–1,860 MHz with Ampere (depending on the model), to a range of 2,475–2,610 MHz with Ada. That's on average 40 to 50 percent higher clocks, though the real-world clocks for both Ampere and Ada tend to be around 200 MHz higher than the official boost clocks.
Ada Massively Boosts Compute Performance

With the high-level overview out of the way, let's get into the specifics. The most noticeable change with Ada GPUs will be the number of SMs compared to the current Ampere generation. At the top, AD102 potentially packs 71% more SMs than the GA102. Even if nothing else were to significantly change in the architecture, we would expect that to deliver a huge increase in performance.
That will apply not just to graphics but to other elements as well. Most of the calculations haven't changed from Ampere, though the tensor cores now support FP8 (with sparsity) to potentially offer double the FP16 performance. Each 4th generation tensor core can perform 256 FP16 calculations per clock, double that with sparsity, and double that again with FP8 and sparsity. The RTX 4090 has theoretical deep learning/AI compute of up to 661 teraflops in FP16, and 1,321 teraflops of FP8 — and a fully enabled AD102 chip could hit 1.4 petaflops at similar clocks.
The full GA102 in the RTX 3090 Ti by comparison tops out at around 321 TFLOPS FP16 (again, using Nvidia's sparsity feature). That means RTX 4090 delivers a theoretical 107% increase, based on core counts and clock speeds. The same theoretical boost in performance applies to the shader and ray tracing hardware as well, except those are also changing.
The GPU shader cores have a new Shader Execution Reordering (SER) feature that Nvidia claims can improve general performance by 25%, and can improve ray tracing operations by up to 200%. Unfortunately, support for SER will require developers to use proprietary Nvidia extensions, so existing games won't necessarily benefit.
The RT cores meanwhile have doubled down on ray/triangle intersection hardware (or at least the throughput per core), plus they have a couple more new tricks available. The Opacity Micro-Map (OMM) Engine enables significantly faster ray tracing for transparent surfaces like foliage, particles, and fences. The Displaced Micro-Mesh (DMM) Engine on the other hand optimizes the generation of the Bounding Volume Hierarchy (BVH) structure, and Nvidia claims it can create the BVH up to 10x faster while using 20x less (5%) memory for BVH storage. Again, these require that developers make use of the new features, so existing ray tracing games won't benefit without a patch.
Together, these architectural enhancements should enable Ada Lovelace GPUs to offer a massive generational leap in performance. Except it will be up to developers to enable most of them, so uptake might be rather diminished.
Ada Lovelace ROPs
Ada's ROP counts are going up quite a bit in some cases, particularly on the top model RTX 4090. As with Ampere, Nvidia ties the ROPs to the GPCs, the Graphics Processing Clusters, but some of these can still be disabled. Each GPC typically gets 16 ROPs.
The AD102 has up to 144 SMs with 12 GPCs of 12 SMs each. That yields 192 ROPs as the maximum, though the final number on the RTX 4090 is 11 GPCs and 176 ROPs. RTX 4080 and 4080 Super have seven GPCs, just like GA102, though in an odd change of pace it appears one of the GPC clusters only has 8 SMs while the other six have up to 12 SMs. Regardless, all seven are enabled for the 4080 cards and yield 112 ROPs; the 4070 Ti Super meanwhile has one fewer GPC and 96 ROPs.
AD104 in the RTX 4070 Ti and 4070 Super uses five GPCs of 12 SMs, with 80 ROPs; the vanilla 4070 trims that to four GPCs and 64 ROPs. And wrapping things up, but AD106 and AD107 have three GPCs and 48 ROPs for all three 4060-class cards.
Memory Subsystem: GDDR6X Rides Again

Last year, Micron announced it has roadmaps for GDDR6X memory running at speeds of up to 24Gbps. The RTX 3090 Ti only uses 21Gbps memory, and Nvidia is currently the only company using GDDR6X for anything. That immediately raises the question of what will be using 24Gbps GDDR6X, and the only reasonable answer seems to be Nvidia Ada. The lower-tier GPUs are more likely to stick with standard GDDR6 rather than GDDR6X as well, which tops out at 20Gbps and is used in AMD's RX 7900 XTX/XT cards.
Officially, the RTX 4090, 4070 Ti/Super, and 4070/Super all use 2GB chips rated for 21Gbps. The RTX 4080/Super are the exception, featuring 2GB chips rated for 22.4Gbps and 23Gbps. Except, Micron doesn't make such chips, so they're actually 24Gbps chips that are clocked more conservatively. Anecdotally, in our disassembly of multiple RTX 40-series GPUs, we've noticed that some of the "21Gbps" cards have memory that runs cooler and overclocks better, hitting up to 25Gbps. We assume Micron is just down-binning some chips and that yields on the 24Gbps memory are quite good now.
Having the same peak bandwidth for the 4090 and 3090 Ti represents a bit of a problem, as GPUs generally need compute and bandwidth to scale proportionally to realize the promised amount of performance. The RTX 3090 Ti for example has 12% more compute than the 3090, and the higher clocked memory provides 8% more bandwidth. Based on the compute details shown above, there's a huge disconnect brewing. The RTX 4090 has around twice as much compute as the RTX 3090 Ti, but it offers the same 1008 GB/s of bandwidth.
There's more room for bandwidth to grow on the lower tier GPUs, as the current RTX 3050 through RTX 3070 all use standard GDDR6 memory, clocked at 14–15Gbps. GDDR6 running at 20Gbps is available, and Nvidia bumped the clocks on the 4060-class cards to 18Gbps on the 4060 Ti and 17Gbps on the vanilla 4060. If Nvidia needed more bandwidth, it could have tapped GDDR6X for the lower tier GPUs as well, but that doesn't seem to be necessary.
There is a problem with Nvidia's VRAM configurations, however: There's simply not 'enough' VRAM capacity on some of the models. The 4070 Ti Super addressed that deficiency with 16GB, but the 4080 and 4080 Super remain at the same 16GB. The 4070 through 4070 Ti are all using 12GB on a 192-bit interface, which is sufficient for now but could prove problematic in the future. Worse yet is the 128-bit interface and 8GB on the 4060 and 4060 Ti, with the latter being particularly galling. The 3060 had 12GB, so this represents a generational step backward. The RTX 4060 Ti 16GB only partially rectifies the situation by doubling the VRAM per channel.
Put succinctly, we would have much rather seen a 192-bit interface with AD106, 256-bit on AD104, and 320-bit on AD103. It would have improved the capacity story tremendously, and Nvidia could have cut the physical L2 to 6MB per 32-bit interface to keep die size in check. That it didn't represents a form of hubris in our book.
The good news is that Nvidia doesn't need massive increases in pure memory bandwidth, because instead it reworked the architecture, similar to what we saw AMD do with RDNA 2 compared to the original RDNA architecture. Specifically, it packed in a lot more L2 cache to relieve the demands on the memory subsystem — though this does nothing for the lack of VRAM capacity on certain models.
Ada Cashes in on L2 Cache
One great way of reducing the need for more raw memory bandwidth is something that has been known and used for decades. Slap more cache on a chip and you get more cache hits, and every cache hit means the GPU doesn't need to pull data from the GDDR6/GDDR6X memory. A large cache can be particularly helpful for gaming performance. AMD's Infinity Cache allowed the RDNA 2 chips to basically do more with less raw bandwidth, and the Nvidia Ada L2 cache shows Nvidia has taken a similar approach.
AMD uses a massive L3 cache of up to 128MB on the Navi 21 GPU, with 96MB on Navi 22, 32MB on Navi 23, and just 16MB on Navi 24. AMD also has 96MB of L3 cache on the newer Navi 31. Surprisingly, even the smaller 16MB cache does wonders for the memory subsystem. We didn't think the Radeon RX 6500 XT was a great card overall, but it basically keeps up with cards that have almost twice the raw memory bandwidth.
The Ada architecture pairs up to an 8MB L2 cache with each 32-bit memory controller, or 16MB per 64-bit controller. That means the cards with a 128-bit memory interface get up to 32MB of total L2 cache, and the 384-bit interface on AD102 has up to 96MB of L2 cache. Except, part of the L2 cache blocks can also be disabled, so the RTX 4090 only has 72MB of L2 cache (twelve blocks of 6MB instead of 8MB), and some of the other Ada models take a similar approach.
While that's less than AMD's RDNA 2 Infinity Cache in many cases, AMD also dropped to 96MB total L3 cache for its top RX 7900 XTX. We also don't know latencies or other aspects of the design yet. L2 cache tends to have lower latencies than L3 cache, so a slightly smaller L2 could definitely keep up with a larger but slower L3 cache, and as we saw with RDNA 2 GPUs, even a 16MB or 32MB Infinity Cache helped a lot.
If we look at AMD's RX 6700 XT as an example. It has about 35% more compute than the previous generation RX 5700 XT. Performance in our GPU benchmarks hierarchy meanwhile is about 32% higher at 1440p ultra, so performance overall scaled pretty much in line with compute. Except, the 6700 XT has a 192-bit interface and only 384 GB/s of bandwidth, 14% lower than the RX 5700 XT's 448 GB/s. That means the big Infinity Cache gave AMD at least a 50% boost to effective bandwidth.
In general, it looks like Nvidia gets similar results with Ada, and even without wider memory interfaces the Ada GPUs should still have plenty of effective bandwidth. It's also worth mentioning that Nvidia's memory compression techniques in past architectures have proven capable, so slightly smaller caches compared to AMD may not matter at all.
RTX 40-Series Gets DLSS 3



One of the big announcements with the RTX 40-series and Ada Lovelace is DLSS 3, which will only work with RTX 40-series graphics cards. Where DLSS 1 and DLSS 2 work on both RTX 20- and 30-series cards, and will also work on Ada GPUs, DLSS 3 fundamentally changes some things in the algorithm and apparently requires the new architectural updates.
Inputs to the DLSS 3 algorithm are mostly the same as before, but now there's an updated Optical Flow Accelerator (OFA) that takes two prior frames and generates additional motion vectors that can then feed into the Optical Multi Frame Generation unit. Combined with DLSS performance mode upscaling, Frame Generation means the GPU potentially only has to actually render 1/8 of the pixels that get sent to the screen.
Incidentally, the OFA is not new with Ada. Turing and Ampere also had a fixed function OFA block, only it wasn't as performant or as capable. Typical use cases for OFA in the past included reducing latency in augmented and virtual reality, improving smoothness of video playback, enhancing video compression efficiency, and enabling video camera stabilization. It was also used with automotive and robotic navigation, and video analysis and understanding.
The Ampere generation upgraded the OFA to a 126 teraops (INT8) fixed function unit, and now Ada boosts the OFA up to 305 teraops. The added performance and other enhancements allow it to be used to create the optical flow field that’s part of DLSS 3 Frame Generation. While the higher performance and capabilities of the Ada OFA are currently required for DLSS 3, there’s a bit of wiggle room. Nvidia’s Bryan Catanzaro, VP of Applied Deep Learning Research, tweeted that it was “theoretically possible” for DLSS 3 to eventually work on Ampere GPUs. It would likely run at lower quality and performance levels, however, and it may never actually happen.
We've now had a chance to see how DLSS 3 looks and feels in action. It's not quite as amazing as Nvidia's claims. Because there's no additional user input factored into the generated frames, plus the extra two frames of latency (relative to the generated frame rate), DLSS 3 can look better than it feels. Take a game like A Plague Tale: Requiem running at 100 fps with DLSS 2 upscaling, and Frame Generation can boost that to 140–150 fps... but it feels more like maybe 110~120 fps at best, in our opinion. At lower pre-FrameGen framerates, like say 30 fps, you might get double the performance to 60 fps, but it will still feel like 30 fps.
DLSS 3 currently requires RTX 40-series cards to run, at least with Frame Generation enabled. That will be an extra setting users can choose to enable; without that, DLSS 3 still supports the core DLSS 2 upscaling algorithm and also requires that developers use Nvidia Reflex, so developers opting for DLSS 3 support RTX 40-series as well as previous RTX series cards.
Note that there's also now DLSS 3.5 Ray Reconstruction, which is completely different from DLSS 3. Ray Reconstruction works with all Nvidia RTX GPUs, even the original 20-series parts from two generations back. However, it's also wholly focused on improving ray tracing quality — it won't do anything for pure rasterization games. It can also improve performance a bit, but that's mostly limited to games with full path tracing like Cyberpunk 2077 in RT-Overdrive mode, or Alan Wake 2.
Ada Gets AV1 Encoding, Times Two
Nvidia's GeForce RTX 4090, 4080, and 4070 Ti graphics cards — plus the two newer Super variants — will feature two of its eighth-generation Nvidia Encoder (NVENC) hardware units. For the RTX 4070 Super and lower models, there's only a single NVENC unit. These will also have support for AV1 encoding, similar to Intel Arc — except there are two instead of just one. We've recently conducted in-depth testing of video encoding performance and quality, comparing the latest GPUs to previous generations.
AV1 encoding improves efficiency by 40% according to Nvidia, but that appears to be compared with H.264 (it's mostly similar in bitrates and efficiency to HEVC/H.265). That means any livestreams that support the codec would look as if they had a 40% higher bitrate than the current H.264 streams. Of course, the streaming service will need to support AV1 for this to matter.
The two encoders can split up work between them, so encoding performance is potentially doubled for any workload, even if the GPU is only encoding a single stream. Or at least that's the theory; in practice, we didn't see any major change when using ffmpeg compared to previous NVENC speeds. Video editors can benefit from the performance boost, and Nvidia worked with DaVinci Resolve, Handbrake, Voukoder, and Jianying to enable support.
GeForce Experience and ShadowPlay also use the new hardware, allowing gamers to capture gameplay at up to 8K and 60 fps in HDR. Perfect for the 0.01% of people that can view native 8K content! (If you build it, they will come...) Also, the NVENC units can still handle H.264, HEVC, and other formats just fine.
Ada Power Consumption

Early reports of 600W and higher TBPs (Total Board Power) for Ada appear to be mostly unfounded, at least on the reference Founders Edition models. In fact, after testing six different RTX 4090 cards, even with manual overclocking we didn't consistently break 600W. The RTX 4090 has the same 450W TGP as the outgoing RTX 3090 Ti, while the RTX 4080 drops that to just 320W, the RTX 4070 Ti has a 285W TGP, and RTX 4070 lands at 200W. Those are for the reference Founders Edition models, however.
As we've seen with RTX 3090 Ti and other Ampere GPUs, some AIB (add-in board) partners are more than happy to have substantially higher power draw in pursuit of every last ounce of performance. RTX 4090 custom cards that draw up to 600W certainly aren't out of the question, and there are a few select models with dual 16-pin connectors. (Hubris, again!)
It all goes back to the end of Dennard scaling, right along with the death of Moore's Law. Put simply, Dennard scaling — also called MOSFET scaling — observed that with every generation, dimensions could be scaled down by about 30%. That reduced overall area by 50% (scaling in both length and width), voltage dropped a similar 30%, and circuit delays would decrease by 30% as well. Furthermore, frequencies would increase by around 40% and total power consumption would decrease by 50%.
If that all sounds too good to be true, it's because Dennard scaling effectively ended around 2007. Like Moore's Law, it didn't totally fail, but the gains became far less pronounced. Clock speeds in integrated circuits have only increased from a maximum of around 3.7GHz in 2004 with the Pentium 4 Extreme Edition to today's maximum of 5.5GHz in the Core i9-12900KS. That's still almost a 50% increase in frequency, but it's come over six generations (or more, depending on how you want to count) of process node improvements. Put another way, if Dennard scaling hadn't died, modern CPUs would clock as high as 28GHz. RIP, Dennard scaling, you'll be missed.
It's not just the frequency scaling that died, but power and voltage scaling as well. Today, a new process node can improve transistor density, but voltages and frequencies need to be balanced. If you want a chip that's twice as fast, you might need to use nearly twice as much power. Alternatively, you can build a chip that's more efficient, but it won't be any faster. Nvidia seems to be going after more performance with Ada, though it hasn't completely tossed efficiency concerns out the window.
Just look at the RTX 4070 Ti as an example. Our testing shows that it's close to the previous generation RTX 3090 Ti in performance, while drawing 37% less power. In some cases, like with DLSS 3 and heavy RT workloads, it can even double the performance while still using less power. The RTX 4080 meanwhile is the most efficient GPU we've tested to date.
But going back to the RTX 4090, even if you're 'only' pulling 450W of power over the 16-pin connector, that's a lot of current in a small area. It probably shouldn't have been a surprise when 16-pin adapters started melting on 4090 cards, and while a revised 12V2x6 connector was later created, that didn't fix the issue — and despite what Nvidia says, we don't think it's all due to user error when inserting the connector. Our (original) 4090 Founders Edition still gets quite toasty on the 16-pin adapter, to the tune of 55C. That's not enough to melt it, but it is uncomfortably hot.
RTX 40-Series Pricing

How much does the RTX 40-series GPUs cost? The short answer, and the true answer, is that they costs as much as Nvidia and retailers can get away with charging. Nvidia launched Ampere with one set of financial models, and those proved to be completely wrong for the Covid pandemic era. Real-world prices shot up and scalpers profiteered, and that was before cryptocurrency miners started paying two to three times the official recommended prices.
The good news is that GPU prices have come down, and Ethereum mining has ended. That in turn has absolutely killed GPU profitability for mining, with most cards now costing more to run than they could make off the endeavor. That's all great to hear, but it still doesn't guarantee reasonable prices.
What do you do when you have a bunch of existing cards to sell? You make the new cards cost more. We're seeing that with the launch prices on the RTX 40-series, from the top RTX 4090 through the RTX 4070. The 4090 ostensibly costs $1,599, $100 more than the 3090 launch price and far out of reach of most gamers. The RTX 4080 isn't much better at $1,199, and the RTX 4070 Ti costs $799, $100 more than the RTX 3080 10GB launch MSRP and $200 more than the outgoing RTX 3070 Ti — and it wasn't until late 2022 that we even saw 30-series cards sell at retail for close to their MSRPs!
It looks like Nvidia managed to clear out enough of its existing RTX 30-series inventory, and the RTX 40-series cards are maintaining their high prices. Most are now available starting at MSRP, or at least close to it, though the RTX 4090 can still command a premium. That's likely because it's also being picked up for professional work, including AI and deep learning research. The lesser RTX 4060 Ti and 4060 are at least bringing Ada down to similar price points as their predecessors.
Overall, generational GPU prices have gone up with Ada and the RTX 40-series (the 4060-series being the exception). Nvidia also has to compete with AMD and the Radeon RX 7000-series and RDNA 3 GPUs, but those are also expensive. Nvidia was slower to push out additional GPUs like the RTX 4070 and below, though the mainstream 4060 Ti and below are back to price parity with their predecessors, and the Super refresh further adjusted prices in the right direction.
Founders Edition Design Changes

Nvidia made a lot of claims about its new Founders Edition card design at the launch of the RTX 3080 and 3090. While the cards generally work fine, what we've discovered over the past two years is that traditional axial cooling cards from third party AIC partners tend to cool better and run quieter, even while using more power. The GeForce RTX 3080 Ti Founders Edition was a particularly egregious example of how temperatures and fan speeds couldn't keep up with hotter running GPUs.
The main culprit seems to be the GDDR6X memory, and Nvidia won't be packing more GDDR6X into Ada than in Ampere, at least in terms of the total number of chips. However, Nvidia does note that it has worked with Micron (the exclusive manufacturer of GDDR6X) to reduce power consumption from the latest generation chips. That should certainly help matters, and while Micron does make 24Gbps GDDR6X, so far Nvidia isn't going that high on memory clocks.
RTX 4090 will have twelve 2GB chips, just like the 3090 Ti, while the 4080 cuts that to eight chips and the 4070 Ti only has to cool six chips. With a process shrink from Micron on the GDDR6X chips, plus better thermal pads, we get RTX 40-series cards that generally don't run nearly as hot as the previous models. Nvidia also reduced thermal pad thickness with the RTX 40-series to better aid in heat transfer from the memory to the heatsink.
It's interesting to note that of the six RTX 4090 cards we tested, about half came with a different class of GDDR6X memory. These cards tended to show VRAM temperatures peaking at 65–70 degrees Celsius, while the other cards would reach 80–85C. Our assumption is that the lower temperature cards are actually using Micron's 24Gbps chips with an improved process node, just marked and sold as 21Gbps. The RTX 4080 so far is the only card to require faster chips, and those cards also tend to hit <65C on the VRAM. The other models seem to be using the same 2GB chips as the RTX 3090 Ti.
As for card designs, even the RTX 4080 gets in on the triple-slot action this round, which is an interesting change of pace. It's 'only' a 320W TBP, but then the 3080 FE and 3080 Ti FE always ran more than a little toasty. The 285W TBP on the 4070 Ti may get the two-slot treatment from some of the AIB partners, but Nvidia won't be making a 4070 Ti Founders Edition — that particular GPU will only come from third party cards. The RTX 4070 does have a Founders Edition, and the RTX 4060 Ti 8GB will have a Founders Edition as well. The RTX 4060 Ti 16GB and the RTX 4060 will only be offered as custom cards from Nvidia's AIB partners.
Ada GPU Release Dates
Now that the big reveal and initial launches are over, we know that the RTX 4090 arrived on October 12, 2022 and the RTX 4080 launched on November 16, 2022. The RTX 4070 Ti arrived on January 5, 2023 (after changing the name from RTX 4080 12GB and dropping the MSRP $100). The remaining models mostly arrived in 2023 as well. RTX 4070 landed on April 13, the RTX 4060 Ti 8GB launched on May 24, RTX 4060 Ti 16GB landed on July 18, and RTX 4060 came out June 29.
Nvidia refreshed the "high-end" cards in January 2024, with the RTX 4070 Super on January 17, the 4070 Ti on January 24, and the 4080 Super on January 31. Unless something changes in the next few months, like a 'secret' reveal of a new Titan RTX at GTX 2024, we think that wraps up the 40-series desktop parts. (There's also an RTX 4090D for China, to comply with export restrictions, which became available on December 28, 2023.)
There are no true budget offerings from Nvidia to take over the GTX 16-series. The best we got was a belated RTX 3050 6GB card, which is pretty anemic but at least it costs $180. It's also slower than an RTX 2060 6GB, if you're wondering. Maybe Nvidia will still do an RTX 4050 6GB at some point, but that remains a question mark.
Competition in the GPU Space

Nvidia has been the dominant player in the graphics card space for a couple of decades now. It controls roughly 80% of the total GPU market, and 90% or more of the professional market, which has largely allowed it to dictate the creation and adoption of new technologies like ray tracing and DLSS. However, with the continuing increase in the importance of AI and compute for scientific research and other computational workloads, and their reliance on GPU-like processors, numerous other companies are looking to break into the industry, chief among them being Intel.
Intel hadn't made a proper attempt at a dedicated graphics card since the late 90s, unless you count the abandoned Larrabee. This time, Intel Arc Alchemist appears to be the real deal — or at least the foot in the door. Intel offers good media capabilities, and Arc's gaming and general compute performance are fine, but they're certainly not sufficient to compete with high-end AMD and Nvidia cards. Instead, Intel is going for the mainstream to budget sector... for now.
But Arc Alchemist is merely the first in a regular cadence of GPU architectures that Intel has planned. Battlemage could easily double down on Alchemist's capabilities, and if Intel can get that out sooner than later, it could actually be a threat at some point. For now, Alchemist can at best try to take on the RTX 4060... and lose on performance, but maybe get a nod of approval for pricing.
AMD isn't standing still either, and it successfully launched its RDNA 3 architecture starting in December 2022. AMD has moved to TSMC's N5 node for the GPU chiplets, but it will also use the N6 node for the memory chiplets. AMD still refuses to put any significant amount of deep learning hardware into its consumer GPUs (unlike its MI200 series), however, which allows it to focus on delivering performance without worrying as much about upscaling — though FSR 2.0 does cover that as well and works on all GPUs. But in the AI space, that means AMD's consumer GPUs are falling behind.
There's also no question that Nvidia currently delivers far superior ray tracing performance than AMD's RX 7000- and 6000-series cards. AMD hasn't been nearly as vocal about ray tracing hardware or the need for RT effects in games. Intel for its part delivers decent (mainstream) RT performance, but only up to the level of the RTX 3060, give or take. But as long as most games continue to run faster and look good without RT effects, it's an uphill battle convincing people to upgrade their graphics cards.

Nvidia RTX 40-Series Closing Thoughts
We had two long years of GPU droughts and overpriced cards for Nvidia's previous generation Ampere / RTX 30-series GPUs. The end of 2022 marked the arrival of the first next-gen GPUs, but they were all very expensive, starting at $800 minimum. The RTX 40-series Ada Lovelace GPUs are better in terms of real-world availability than the prior generation, though prices are all higher.
Read our full reviews of the RTX 40-series cards for additional testing and results:
GeForce RTX 4090
GeForce RTX 4080 Super
GeForce RTX 4080
GeForce RTX 4070 Ti Super
GeForce RTX 4070 Ti
GeForce RTX 4070 Super
GeForce RTX 4070
GeForce RTX 4060 Ti 16GB
GeForce RTX 4060 Ti
GeForce RTX 4060
- MORE: Best Graphics Cards
- MORE: GPU Benchmarks and Hierarchy
- MORE: All Graphics Content
