How Redundant Arrays Work
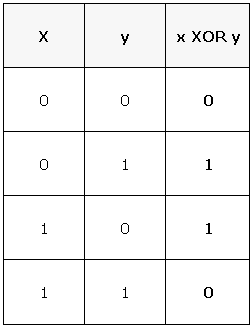
The challenge with redundant arrays such as RAID 5 or RAID 6 is to create parity bits on the fly, and to be able to recreate stored data bits using the generated parity bits. The basic idea behind this parity generation is the "exclusive OR" (XOR) Boolean operation. The truth table below shows how it works.
Other than parity generation, a RAID 5 stripe set is no different from a RAID 0, except that all but one hard drives are used; it's all but two drives in case of RAID 6. Parity generation involves an entire stripe that is going to be distributed across the array. A stripe consists of n-1 data blocks, where n is the total number of array drives, and the parity block that is generated always adds to a stripe as its last block.
A block is the data chunk that is stored onto one drive, and is typically between 4 and 64 kB in size. As we already outlined, this parity block is stored in an alternating manner in order to avoid creating a bottleneck; this becomes more important the more drives you use.
The generation or parity data as well as the reverse process (recreation of stored data bits after a partial data loss) requires intensive computing. Professional RAID solutions have an on-chip RISC processor that performs these binary XOR operations and reduces the CPU load for the host computer. These units are typically called "XOR engines" or "XOR accelerators", while the host adapters are referred to as "hardware-based RAID controllers".
The term "software-based RAID" is often used to describe XOR processing by the system processor. This is a popular solution because it is cost effective; no additional hardware is needed. At the same time, it will only perform well with a fast host system CPU and with no other demanding tasks to take care of. In fact this should really be called "host-based RAID", because a software RAID would be an array that is entirely created by the operating system only.
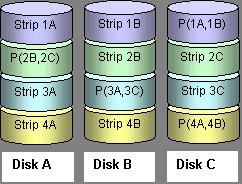
Source: Adaptec. This is how a RAID 5 works. A RAID 6 generates another layer of parity data.
