Memory Optimizations

nForce4 Intel Edition operates each DIMM with a dedicated address bus.
NVIDIA decided to make the nForce4 IE work with smaller chunks of information, to enable more efficient dual channel memory interleaving. The chipset uses a burst length of four rather than Intel's eight. In addition, 1T addressing is executed by running dedicated address buses for each DIMM. This access scheme results in four read commands needed to read two 64 Byte lines, while 1T addressing allows the chipset to interleave four memory cycles with the read command.
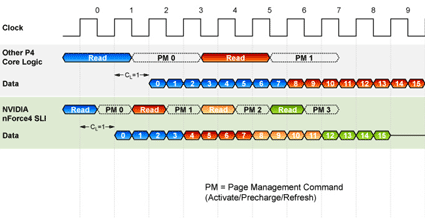
A burst length of four in combination with the 1T command obviously makes sense: two 64 Byte lines an be read in fewer clock cycles.
New Prefetcher: DASP 3.0
Main memory is one of the major bottlenecks in computer systems today. For this reason, all current processors include high-speed buffer memories split into two different levels. The first level cache (L1) is small and extremely fast, while the level 2 (L2) cache is slower but much larger - up to 2 MB in modern desktop processors. The purpose of the caches is to provide data that is either repeatedly used over a short period of time or data that is in close vicinity to other data recently used.
With a little luck, data that is requested by the processor will be in the cache, which is called a "page hit" - the corresponding memory page is open and the content can be transferred instantly. But if requested data is not available - a cache miss - a memory access must be executed. The second scenario is a page miss with closed page. Here, the page needs to be opened in order to access data. However, the worst case scenario is a page miss with a wrong page open; that page has to be closed before accessing the right page.
In order to avoid time consuming page misses, processors have built-in prefetch units. They predict the memory pages that will be required, and perform the access ahead of time. NVIDIA's Dynamic Adaptive Speculative processor (DASP) is a sophisticated feature that builds on top of this concept. It was first introduced with the nForce IGP/SPP, and now version 3.0 has been deployed. Considerable changes were necessary since obviously it is not that easy to predict the operation of a new CPU. In addition, features like Hyper Threading and upcoming dual core processors make the whole process much more difficult.
DASP 3.0 is able to track each core and each thread in order to prefetch data. An arbiter manages the available prefetching units, and acts as a load balancer to avoid other components being excluded from memory access for too long. It also controls prefetch priorities, and the prefetch units have access to different prefetching algorithms and may even combine them.
