NetBurst Architecture: Now 31 Pipeline Stages
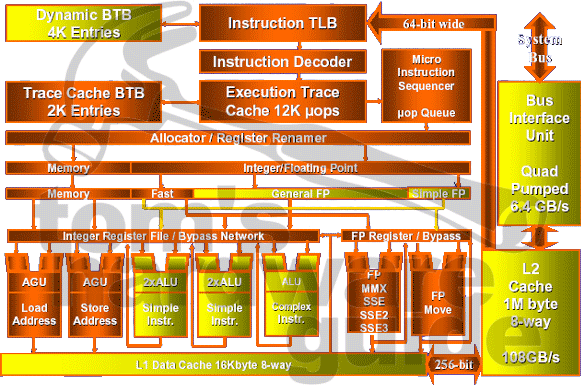
Prescott's block diagram does not differ from Northwood's or Willamette's diagram, since there are no fundamental changes.
Large caches and additional instructions do not necessarily make a fast processor, so let's take a look at the detailed changes that Intel made.
First of all, let's summarize what happens inside the Pentium 4: Instructions are received over the 64 bit wide, 200 MHz and 6.4 GB/s fast system bus. Then they enter the L2 cache. The prefetcher analyses the instructions and activates the BTB (Branch Target Buffer) in order to get a branch prediction, accomplished by a determination on what data could be required next. The modified instruction set is sent through the instruction decoder that translates the x86 data into micro operations.
The x86 instructions can be complex and frequently feature loops, which is why Intel abandoned the classic L1 instruction cache back with the first Pentium 4 Willamette in favor of the Execution Trace Cache. It is based on micro operations and is located behind the Instruction Decoder, making it the much smarter solution by eliminating unnecessary decoding work. The Execution Trace Cache stores and reorganizes chains of multiple micro operations in order to pass them to the Rapid Execution Engine in an efficient manner.
The first noticeable change concerns the Branch Target Buffer and the Instruction Decoder. If the BTB does not provide a branch prediction, the Instruction Decoder will perform a static prediction that is supposed to have only little impact on performance in case the prediction should be wrong. The little impact can be realized by an improved loop detection process. The dynamic branch prediction has also been updated and integer multiplication is now done within a dedicated unit.
Predicting branches is a core element in order to enable high performance. If the processor knows or at least guesses what comes next, it will be able to fill its pipeline in an efficient manner. This has become even more important since the pipeline has been stretched from 20 stages to now 31 stages. Intel tries to reduce the complexity of each stage in order to run higher clock speeds. In exchange, the processor becomes more vulnerable to misprediction.
Now it's quite obvious why Intel tried to increase all caches. In case of misprediction, it's more important than ever to "keep the system running". The right data thus must be available in order to fill the pipeline. In order to support that, the L1 data cache must have an eight-way associativity value associated with the ability to check if the requested data is already located inside the cache.
