
Update 12/22 at 4:31PM ET Spotify has shared the following statement:
"Spotify has identified and disabled the nefarious user accounts that engaged in unlawful scraping. We've implemented new safeguards for these types of anti-copyright attacks and are actively monitoring for suspicious behavior. Since day one, we have stood with the artist community against piracy, and we are actively working with our industry partners to protect creators and defend their rights."
Spotify, the largest music streaming platform in the world with hundreds of millions of active users, and an extensive library of music has allegedly been hacked by Anna's Archive. The shadow library, who labels itself as archivists, has apparently scraped nearly the entirety of the platform, downloading roughly 300 TB of music that is now being distributed illegally via torrents.
"An investigation into unauthorized access identified that a third party scraped public metadata and used illicit tactics to circumvent DRM to access some of the platform’s audio files. We are actively investigating the incident."
Article continues belowThat "some" in the above comment is key because the leaked collection consists of around 86 million files in particular, representing ~37% of all music available on the platform (but 99.9% of listens). Most of them are preserved in Spotify's original OGG Vorbis 160 kbps format, but if any song has a popularity rating of exactly 0, then they've been re-encoded to 75kpbs to save space.
With that, there's 256 million rows of metadata that accounts for 99.6% of all listens on Spotify and it has been complied into query-able SQL databases. The group has done a near-lossless JSON reconstruction of Spotify's API, including 186 million unique ISRCs. — identifiers for individual recordings worldwide; think of them as ISBNs for music. All the album info, artist info, cover art etc., is included.
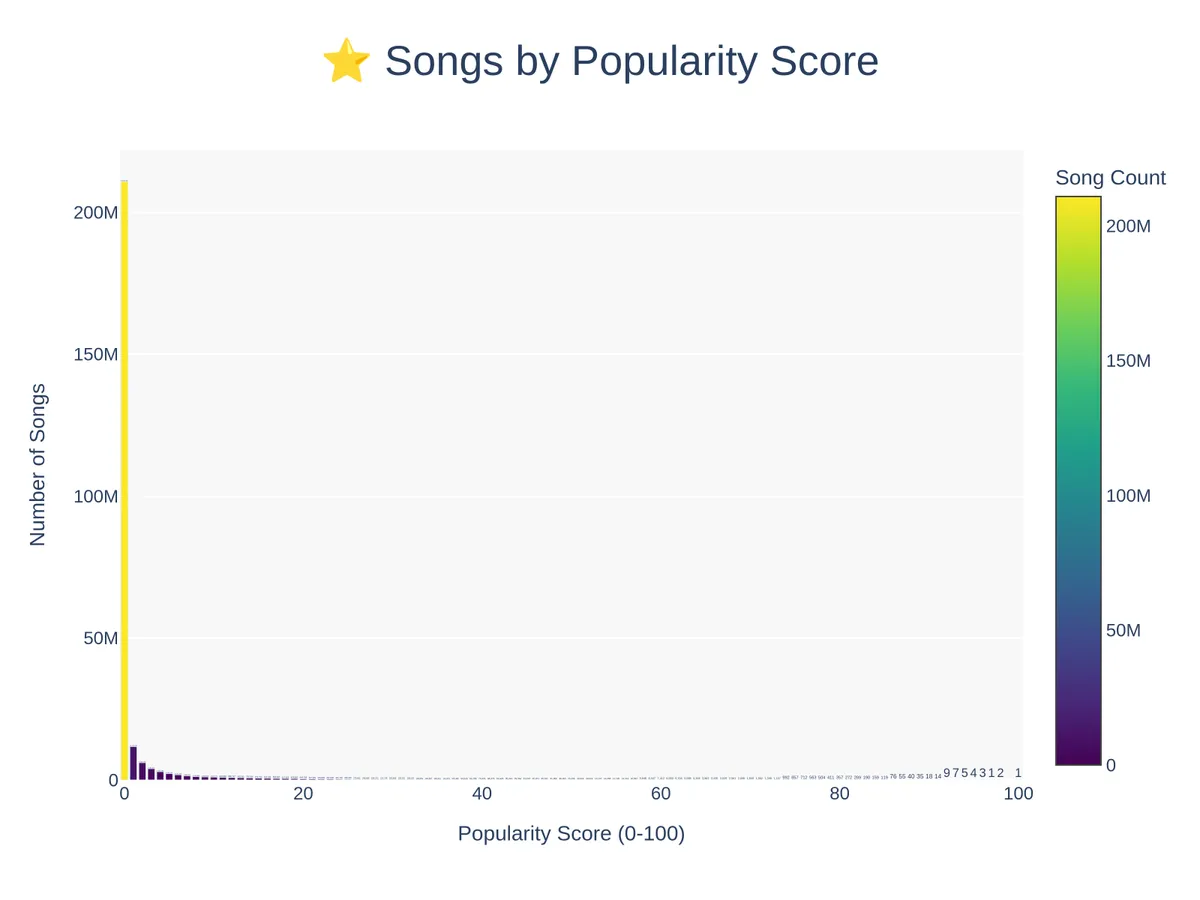
The blog post released by Anna's Archive going over this leak is surprisingly informative, including a bunch of charts that break down how Spotify treats music in general. For instance, around 70% of all songs on the platform barely get any attention, while 0.1% of the tracks are the most popular of all time. Most songs are also singles, rather than part of an album, and 120 BPM is the most common tempo.
Anyhow, the reason for this large-scale hack, as described by Anna's Archive itself, is preservation of music. Since the group is notorious for open-sourcing books without consent, it's applying much of the same logic here, arguing that Spotify's collection is too overtly focused on popular artists and sound quality. There needs to be an "authoritative list of torrents aiming to represent all music ever produced."
The torrents are self-hosted, and the files are packaged using Anna’s Archive Containers (AAC), a custom format the group has used for years. The metadata has already been released while the rest of the data will follow a staggered release pattern in huge chunks, categorized by popularity. Therefore, the aftermath of this scrape will only truly show up down the line.

Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
