Optimizing Page Miss Performance
Many users and even engineers still automatically assume that page hit latency is still the key to DRAM performance. Over the life of the PC, page miss rates have skyrocketed from about 20% up to 70 or 80%. This is a result of the caches. CPU activity that is neatly sequential or localized ends up being serviced by the cache. Accesses that are extremely random in nature have a high probability of missing the cache, and usually result in a page miss when presented to DRAM. The problem grows worse as CPU caches become larger and more efficient.
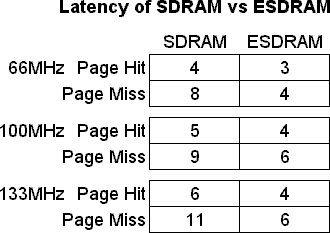
In the table above, ESDRAM shows a page hit rate at all speeds that is one or two clocks faster than SDRAM. But more importantly, when used with an optimized controller, page misses can be serviced as fast as page hits with ordinary SDRAM. This is an amazing feat. (These numbers include a one clock delay for address propagation and decode by the chip set.)
In order to estimate the CPU performance impact of this kind of optimization, I went through a rather exhaustive modeling exercise. I built 16 different model configurations representing different speed grades of the K6, Mendocino and the Pentium2. The speed grades ranged from 233 to 533 MHz at external bus speeds of 66, 100 and 133 MHz. Each entry below is an average of all of the configurations selected for that processor.
There are two tables below. One evaluating the performance impact on standard architecture PCs and another for low cost UMA style systems. Three types of system bandwidth loads are modeled. "2D " represents the CPU performance delta for a typical 2D business application (as simulated by the ZD Labs CPU Mark 32 benchmark). "MM " signifies the CPU performance delta to be had under a multimedia load such as motion video decode. "3D " models the CPU performance impact based on the system bandwidth load of a rather challenging game application.
AGP and UMA bandwidth demand is considered in this model, but not other forms of I/O. For example, if your application spends all of its time waiting for the hard disk, your results will be different.
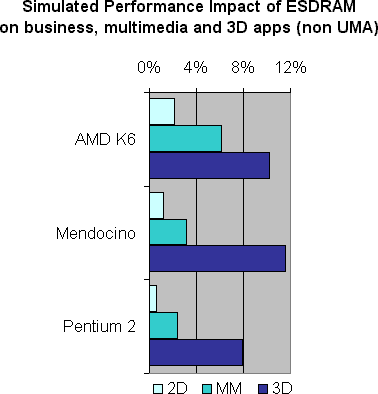
In a standard architecture system (above), the performance impact of an ESDRAM optimized memory controller on ordinary business applications is negligible. For multimedia applications the performance impact grows to 3-6%. 3D graphics applications start to become interesting at 8-12%, a throughput increase equivalent to one CPU speed grade.
For UMA systems, the DRAM bus saturation is inherently higher, and so is the performance impact of ESDRAM. Most business applications are not screaming for more performance, so the small advantage in 2D is still insignificant. Multimedia increases by 8-15%, while 3D jumps to a 15-23% performance advantage. These applications are quite challenging for a UMA system, and ESDRAM offers a valuable performance impact.
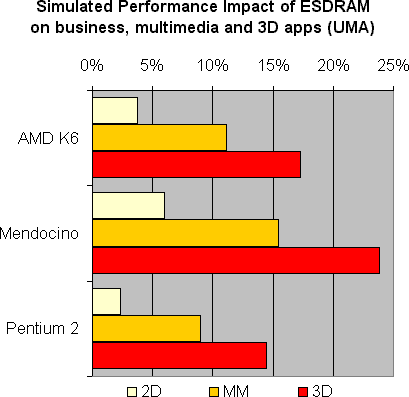
Mendocino is the second processor in Intel's Celeron product line. It is due to its smaller 128K integrated L2 cache that the performance impact is higher for this processor than the others. The highest individual improvement in this simulation was shown by a 333 MHz Mendocino, which resulted in a 34% performance advantage for UMA 3D applications when using ESDRAM as compared to standard SDRAM.
The AMD K6, Cyrix M2, IDT WinChip and Mendocino should all be popular CPUs for the high volume sub $1K market. By offering SDRAM and ESDRAM support for these systems, OEMs will be better able to deliver a broader range of performance with a narrower range of platforms. SDRAM will be the choice for business PCs, and ESDRAM will be an option with faster CPUs or for midrange game PCs.
Though in theory, DDR could be supported in the same way, Rambus and SLDRAM require a completely new controller that is not compatible with SDRAM. Besides, first pass simulations of high bandwidth DRAM show that it offers only about half of the performance benefit of low latency DRAM. I will offer more detailed information on this in the future.