The patent include the idea to leverage stored instructions in a computer system to "assign two threads to processors based on bandwidth utilization of the two threads in combination; determine whether the bandwidth utilization of the two combined threads exceeds a threshold value; use a cache simulator to construct a coupling degree matrix; use a software library to develop said coupling degree matrix; and use the coupling degree matrix to allocate threads to processors when the bandwidth utilization does not exceed said threshold."
Also claimed are instructions that provide information on whether the bandwidth utilization exceeds a threshold of 15 percent, as well as a capability to store "the coupling degree matrix by rating two threads in terms of the total amount of accesses to cache lines shared between two threads," as well as a "scheduler to determine the coupling degree matrix by rating the threads in terms of the total amount of accesses to cache lines."
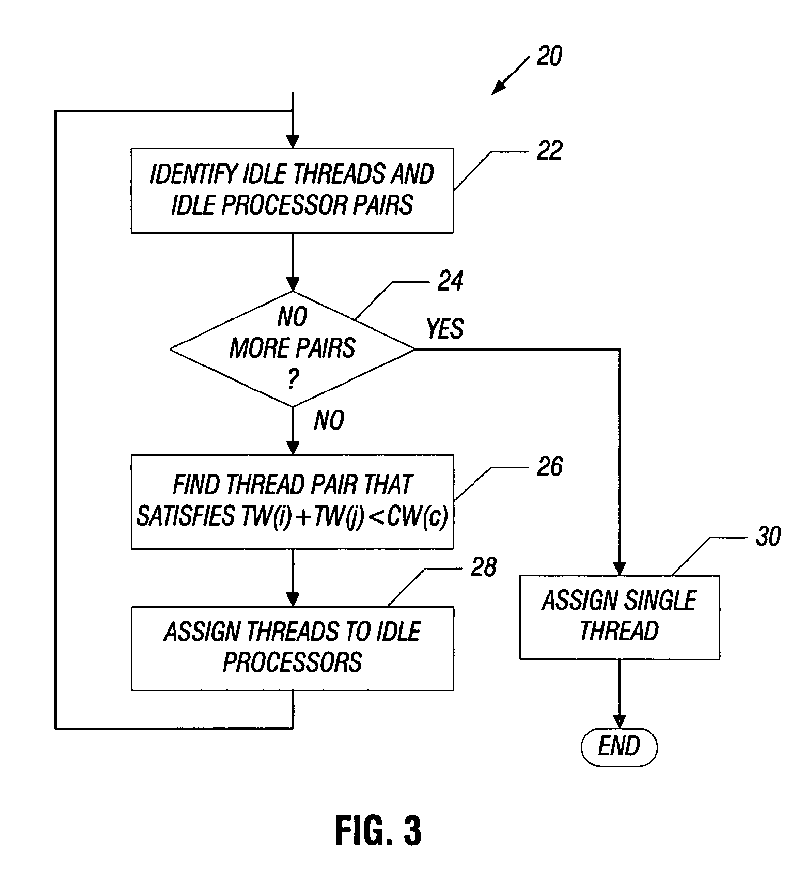
In the scheduling process, idle threads and idle process pairs are first identified and a loop to check for more pairs is launched, after which threads to idle processors are assigned. This process repeats until all process pairs have been covered. As soon as no more pairs are available, the loop may identify an individual thread that is assigned to a process.
The patented scheduler uses information about the location of data between threads and bandwidth demand to evaluate thread allocation for performance purposes. According to the patent, bandwidth utilization is considered the highest priority in determining the thread schedule, followed by data location. The document concludes that, if a bandwidth threshold of co-scheduled threads on one cluster exceeds a certain level, "for example 15 percent", the system would schedule the threads on different clusters. If the utilization is below the defined level, the system assumes that closely coupled threads on one cluster would achieve higher performance.
