


Lunar Lake’s P-cores deliver a 14% average gain in IPC (Instructions Per Cycle), which floats all boats in terms of performance. However, Intel took an unexpected turn in optimizing the cores for a hybrid architecture by removing hyperthreading and all the logic blocks that enable that performance-boosting feature.

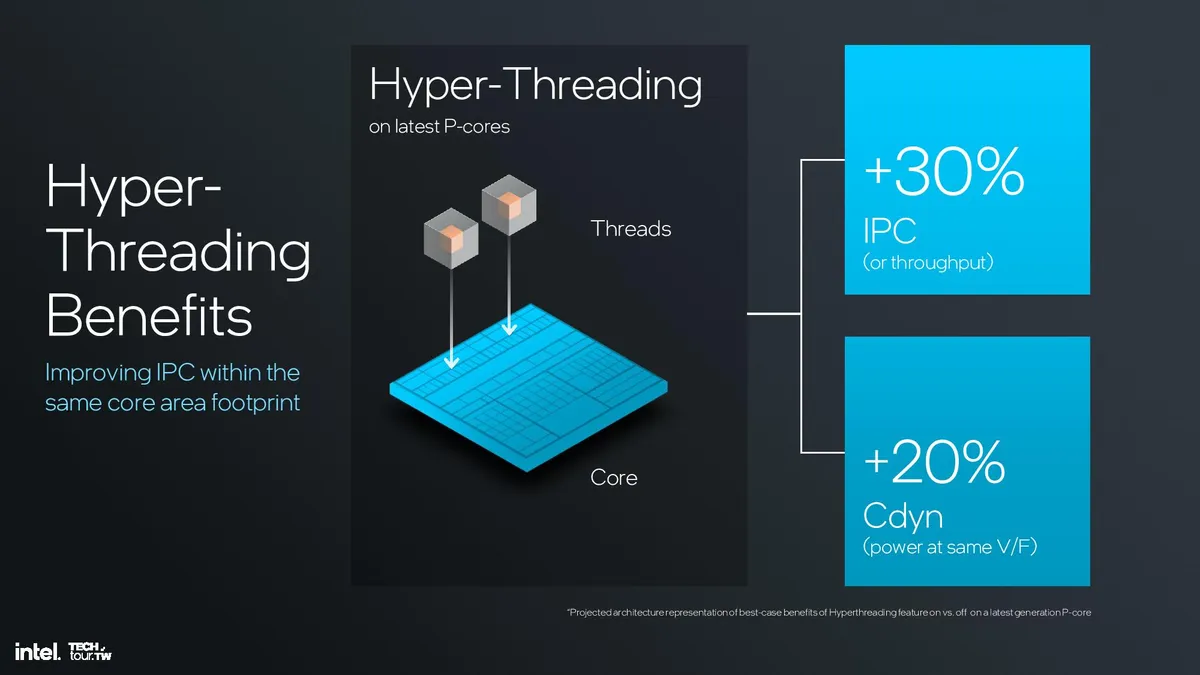





Intel’s architects concluded that hyperthreading, which boosts IPC by ~30% in heavily threaded workloads, isn’t as relevant in a hybrid design that leverages the more power- and area-efficient E-cores for threaded workloads. In fact, threads were typically scheduled into all P-cores first without leveraging the extra threads on the cores, and then spilling additional threads spill over to the E-cores. Only after the E-cores were saturated did additional threads begin to get scheduled into the extra threads available on the P-cores.
Removing the dedicated fairness mechanisms and extra security features required for hyperthreading makes the core leaner, delivering a 15% increase in performance efficiency, 10% increase in performance per area, and a 30% improvement in performance per power per area. This was much more effective than merely disabling hyperthreading while leaving the control circuitry present, as shown in the measurements in the last slide above. The new approach also preserves die area for other additives, like more E-cores or GPU cores.
Intel isn’t discarding hyperthreading for all use-cases — it still sees tremendous value in P-core-only designs. As such, Intel architected two versions of the Lion Cove core, one with and one without hyperthreading, so that the threaded Lion Cove core can be used in other applications, like we see in the forthcoming Xeon 6 processors.
Lion Cove also marks a shift from pre-defined static settings for various operating conditions, such as assigning certain points on the voltage/frequency curve for different thermal and power thresholds. It now uses an AI self-tuning controller to dynamically adapt in a more intelligent manner. Intel’s clock frequencies also used to only be adjustable in 100 MHz increments (bins) but are now tunable in 16.67 MHz bins to provide more fine-grained frequency and power control. Intel credits this with single-digit percentage increases in either power efficiency or performance in some scenarios, and every bit counts in an efficiency-first architecture.












The front end of the microarchitecture fetches x86 instructions and decodes them into microoperations to feed the out of order execution engine. The goal is to saturate the out of order part of the engine to prevent stalls, and that requires fast and accurate branch prediction.
Intel says it widened the prediction block by 8X over the previous architecture while maintaining accuracy. Intel also tripled the request bandwidth from the instruction cache to the L2 and doubled the instruction fetch bandwidth from 64 to 128 bytes per second. Additionally, decode bandwidth was bumped up from 6 to 8 instructions per cycle while the micro-op cache was increased along with its read bandwidth. The micro-op queue was also increased from 144 entries to 192 entries.
Previous P-core architectures had a single scheduler to dispatch instructions across the execution ports, but the design incurred hardware overhead and scalability issues. To address these issues, Intel split the out of order engine into integer and vector domains with independent renamers and schedulers to increase flexibility. A range of improvements were also made to the retirement, instruction window, and execution ports, along with other improvements to the integer and vector execution pipelines (listed in the slides).
The memory subsystem has a new L0 cache level. The architects completely redesigned the data cache to add a 192KB tier between the existing L1 and L2 caches. This resulted in renaming the existing L1 as L0. Ultimately this decreases the average load-to-use time, which increases IPC, and enables increasing the L2 cache capacity without latency sacrifices due to the increased capacity. As a result, L2 cache grows to 2.5MB on Lunar Lake and 3MB on Arrow Lake (they both use Lion Cove for the P-cores).
Intel also switched from using proprietary design tools to industry-standard tools optimized for its use. Intel’s old architectures were designed with “Fubs” (functional blocks) of tens of thousands of cells consisting of manually drawn circuits, but it has now moved to using big, synthesized partitions of hundreds of thousands to millions of cells. The removal of the artificial boundaries improves design time, increases utilization, and reduces area.
This also allowed for the addition of more configuration knobs into the design to spin off customized SoC-specific designs faster, with the lead architect saying this allows for more customization between the cores used for Lunar Lake and Arrow Lake. This design methodology also makes 99% of the design transferable to other process nodes, a key advance that prevents the stumbles we’ve seen in the past where intel’s new architectures were delayed by massive process node delays (as with 10nm, for instance).

The end result of the changes is a 14% increase in IPC at a fixed clock rate over the previous-gen Redwood Cove architecture used in Meteor Lake. Intel also points to overall performance improvements that range from 10% to 18% over Meteor Lake depending upon the operating power of the chip. Notably, these power/performance improvements are based on projections/estimates, so Intel has given itself a +/- 10% margin of error for the metrics on the ‘performance at power’ chart.
