It appears that Apple has kept a closely-guarded secret regarding its new M1 Max silicon. New pics of the underside of the chip reveal that it may actually have an interconnect bus that enables Multi-Chip-Module (MCM) scaling, allowing the company to stack together multiple dies in a chiplet-based design. That could result in chips with as many as 40 CPU cores and 128 GPU cores. Apple has yet to confirm provisions for chiplet-based designs, but the M1 Max could theoretically scale into an "M1 Max Duo" or even an "M1 Max Quadra" configuration, aligning with persistent reports of various chiplet-based M1 designs in the future.
Apple has managed to impress the world not once but twice already with the performance of its Arm-based M1 CPUs. The company's latest M1 Max chip is a force to be reckoned with by itself - the chips' gargantuan 57 billion transistors enable Apple to scale up to 10 CPU cores and either 24 or 32 GPU cores (depending on the configuration you get), all in a single 5nm chip. Adding accommodations for a chiplet-based design would theoretically multiply compute resources, and thus performance.
You guys seeing this or am I just crazy? The actual M1 Max die has an entire hidden section on the bottom which was not shown at all in Apple's official renders of the M1 Max die. Just flip another M1 Max and connect it for an M1 Max Duo chip. Then use I/O die for M1 Max Quadra. https://t.co/McWmofJAls pic.twitter.com/JogRwUGvF6December 2, 2021
The interconnect bus would allow Apple to scale its chips by "gluing together" the appropriate number of M1 Max chips. But, of course, it's not simply a matter of flipping one M1 Max chip and aligning it with the second one; Apple would still have to use specific interposer and packaging options for a chiplet-based design.

Interestingly, Apple's M1 Pro chip (which fits between the M1 and M1 Max SoCs) lacks the interconnect bus — it's actually located in the extended half of the M1 Max (a beefier version of the M1 Pro). This likely means that Apple only expects users that need the additional graphics compute power in its M1 Max (such as graphics or television studios) to require further performance scaling via this chiplet design philosophy.
Marrying two 520 mm^2 Apple M1 Max dies in an "M1 Max Duo" chip could deliver up to 20 CPU cores and 48 or 64 GPU units. It would also require an appropriate doubling of the system's memory to 128 GB. Memory bandwidth should also scale in such a system, up to 800 Gb/s. That seems doable within the current M1 Max design, although the 10,040 mm^2 of Apple silicon would be more expensive, of course.
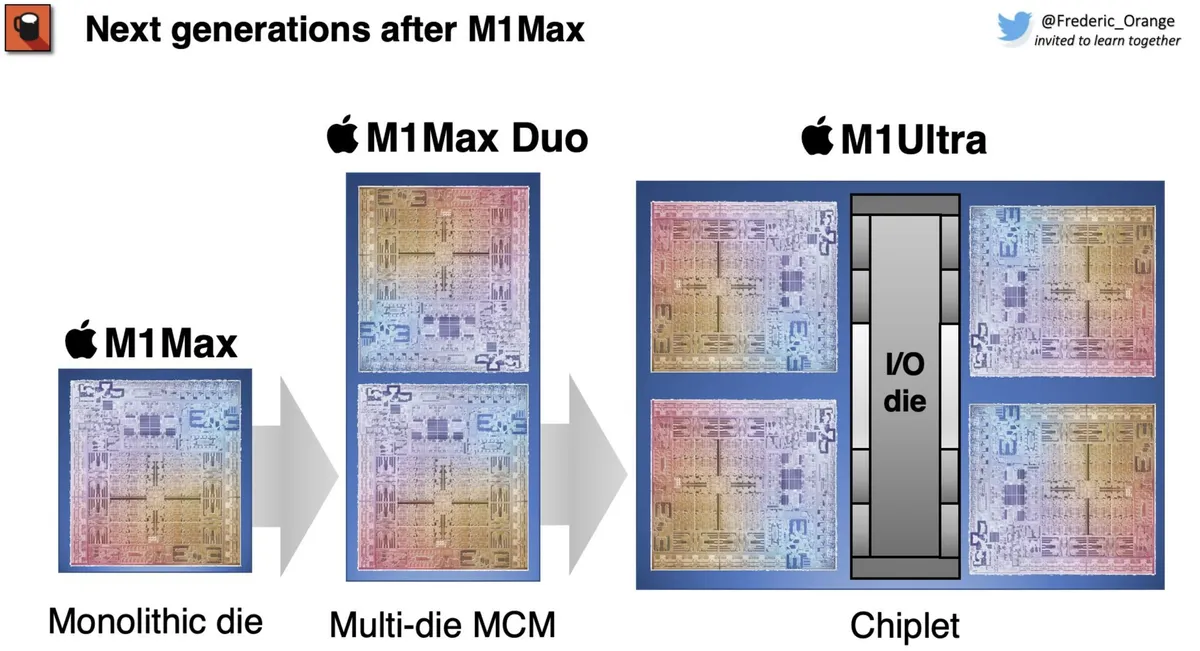
Going for the "M1 Max Quadra" solution with 40 CPU cores and 128 GPU cores would be even more complicated. Perhaps an added I/O die, as the source suggests, is the correct solution, but possibilities abound. Apple could also sustain enough inter-die bandwidth via an I/O technology akin to AMD's Infinity Fabric. Whether or not the larger chips would require an I/O die remains an open question, as other leaks have suggested the design will be expanded in a monolithic design.
Once again noting that Apple’s marketing diagrams do NOT accurately represent the floor plan of its chips, here is a less fanciful interpretation of the Pro Mac SoC rumors.Presenting Jade-C: The building block for Pro Mac SoCs. (M1 included for scale.) pic.twitter.com/Lp8ZBDeLiuMay 21, 2021
It's ultimately unclear how Apple would choose to handle memory bandwidth scaling - and any solution would have very increased platform development costs throughout. But then again, these theoretical "M1 Max Duo" and "M1 Max Quadra" products would cater to a market that cares more about performance and power efficiency than cost.
