
Nvidia announced more details about its new 88-core Vera data center CPUs at GTC 2026 here in San Jose, California, claiming impressive 50% performance gains over standard CPUs, fueled by a 1.5X increase in IPC from its Olympus cores and an innovative high-bandwidth design that Nvidia says delivers the fastest single-threaded performance on the market. The company also unveiled its new Vera CPU Rack architecture, which brings 256 liquid-cooled CPUs into one rack for CPU-centric workloads, claiming a 6X gain in CPU throughput and twice the performance in agentic AI workloads.
The evolution of the Vera CPU and its integration into deployable rack-scale systems marks Nvidia’s entry into direct CPU sales, positioning itself as a competitor to Intel and AMD in the traditional CPU market. That’s not to mention competing against the many flavors of custom Arm processors used by the world’s largest hyperscalers. This doesn’t come as a complete surprise, coming in the wake of the company’s announcement that Meta will now deploy multiple generations of Nvidia CPU-only systems across its infrastructure. Nvidia will also continue to use the CPUs for its own GPU-focused systems, such as the Vera Rubin platform we covered more in depth here.
Article continues belowNvidia Vera CPU specifications and performance
Nvidia designed the Vera CPU to provide the best of many worlds, with the intention of melding the high core counts of hyperscale cloud CPUs with the high single-thread performance of gaming CPUs and the power efficiency of mobile chips, all with the goal of speeding common GPU-driven tasks in agentic AI, training, and inference workloads, such as Python execution, SQL queries, and code compilation.
All told, Nvidia claims 1.5x the performance-per-sandbox over x86 competitors, 3x the memory bandwidth per core, and twice the efficiency. To meet those goals, the company designed an 88-core CPU with 176 threads, an increase over the first-gen Grace’s 72 cores. Nvidia also claims the cores offer a 1.5X improvement in instructions per cycle (IPC) throughput, a massive generational jump relative to other competing architectures, which tend to gain a single-digit or a low-teens percentage increase with each generation. With the previous-gen Grace, Nvidia used off-the-shelf Arm Neoverse cores, but the firm does stipulate that the new Olympus cores found on Vera are ‘Nvidia designed,’ signaling that the company has made custom modifications to the reference design.
The Arm v9.2-A Olympus cores feature spatial multi-threading, which physically isolates the various components of the pipeline by not time-slicing the key elements, like the execution units, caches and register files, with the other thread running on the same core. This contrasts with the standard time-slicing found in other simultaneous multi-threading (SMT) implementations, a process that has the threads take turns utilizing the resources. Spatial Multi-Threading increases Instruction Level Parallelism (ILP), throughput, and performance predictability by pulling instructions from other threads when execution elements are idle, thus ensuring full utilization.
In effect, this allows both threads to truly run simultaneously on a single core, whereas in a standard SMT implementation the threads essentially take turns running on a single core. Naturally, this will be a boon for multi-tenancy environments.

Nvidia arranges all 88 cores in a single domain, so there are no latency-inducing NUMA eccentricities to be found, in stark contrast to current high core-count x86 competitors. This has dramatic implications for latency, predictability, bandwidth, and ease-of-programmability. The firm has not shared the full details of how it accomplished this feat while maintaining adequate latency to each core, but the chip features a new generation of the Nvidia Scalable Coherency Fabric (SCF), a mesh topology built from Arm’s CMN-700 Coherent Mesh Network used in Grace’s Arm Neoverse cores. Arm has moved forward to the newer Neoverse CMN S3 mesh with its latest designs, and Vera likely employs that design, or a variant thereof.
The mesh network can deliver impressive memory throughput to the cores in aggregate, and even more when certain cores are more bandwidth-hungry than others. Grace supported 546 GB/s of memory throughput to the mesh, working out to an average of 7.6 GB/s per core. Vera more than doubles that to 1.2 TB/s of bandwidth fed by 1.5TB of SOCAMM LPPDDR5 modules (a 3x increase in capacity), which works out to an average of 13.6 GB/s per core in full-load conditions. Importantly, the architecture now supports up to 80 GB/s of throughput to any single core when load conditions aren’t consistent across the mesh, an impressive uplift for bandwidth-hungry threads.
The execution pathway includes a 10-wide Instruction Decode unit, a neural branch predictor that supports two branch predictions per cycle, a custom graph database analytics prefetch engine, and a PyTorch-optimized Instruction Buffer.
The chip fully supports Confidential Computing, a notable advance over Grace that allows for fully protected CPU+GPU domains. The CPU also features an NVLink-C2C die-to-die interface with up to 1.8 TB/s of throughput, a doubling of Grace’s 900 GB/s interconnect and seven times faster than PCIe 6.0. It also supports two-processor (2P) configurations.
Overall, Vera supports the full suite of technologies expected from a modern data center processor, including PCIe 6.0 and CXL 3.1 support, but with a bandwidth and latency-focused compute design that positions its uniquely well for use in AI workflows.
The Vera CPU Rack and Benchmark Performance
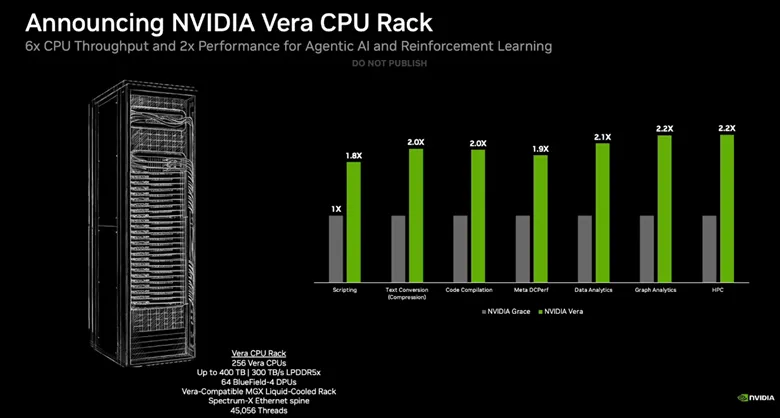
Grace has already served as a fundamental building block in many Nvidia GPU+CPU systems, including some of the fastest AI supercomputers on the planet, but Nvidia’s expanded goal is to leverage Vera in pure-play CPU racks that can be more widely deployed.
The Vera CPU rack meets that goal with 256 liquid-cooled Vera CPUs paired with 74 Bluefield-4 DPUs and ConnectX SuperNIC networking. The rack weighs in with up to 400 TB of LPDDR5 and 300 TB/s of aggregate memory throughput. That feeds the 45,056 threads, which Nvidia says supports 22,500 concurrent CPU environments running independently.
Nvidia shared benchmarks in a wide range of workloads, touting from a 1.8x to 2.2x performance improvement over Grace in scripting, compilation, data analytics, graph analytics, and HPC workloads, among others.
Naturally one would expect this system to be deployed at Meta, which recently announced its partnership with Nvidia for CPU-only systems, but Nvidia says it will also offer the Vera CPU rack system to hyperscalers, including Oracle, Coreweave, Nebius, Alibaba, and others.
A broad range of OEMs and ODMs will also provide single- and dual-socket servers for the broader market for a wide range of use cases, including industry heavyweights like Dell, HPE, Lenovo, Supermicro, Foxconn, and many others. The Vera CPUs will also be used for Nvidia HGX NVL8 systems.
Perhaps most importantly, these racks will also serve as an integral part of Nvidia’s broader Vera Rubin platform, which features seven chips in total, including the Rubin GPU, NVLink6 Switch for rack-scale interconnect, ConnectX-9 SuperNIC for networking, Bluefield 4 DPU, Spectrum-X 102.4T Co-packaged Optics switch, and Nvidia’s Groq 3 LPUs.
The Vera CPUs are in full production now and are slated for deliveries beginning in the second half of this year.

Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
