
EXO Labs' primary project is EXO, an open-source framework for running large language models (LLMs) efficiently across mixed hardware setups. Rather than treating inference as a task bound to a single GPU or accelerator, EXO automatically spreads workloads across whatever devices you have—turning a cluster of desktops, laptops, workstations, servers, tablets, or even smartphones into a cooperative AI mesh. EXO's newest demo combines two of NVIDIA's DGX Spark systems with Apple's M3 Ultra–powered Mac Studio to make use of the disparate strengths of each machine: Spark has more raw compute muscle, while the Mac Studio can move data around much faster. EXO 1.0, currently in early access, blends the two into a single inference pipeline, and it apparently works shockingly well.


In EXO's benchmark with Meta's Llama-3.1 8B model, the hybrid setup achieved nearly a threefold speedup over the Mac Studio alone — matching the DGX Spark's prefill speed while keeping the M3 Ultra's quick generation time. The result is a 2.8× overall gain, and that was with an 8K-token prompt on a relatively modest 8B model. Longer prompts or larger models should see even greater gains.
Article continues belowThis kind of "disaggregated inference" isn't exactly a novelty, but it's still very clever. It hints at a future where AI performance scales not by buying one massive accelerator, but instead by more intelligently orchestrating the hardware you already have. NVIDIA seems to agree: its upcoming Rubin CPX platform will use compute-dense Rubin CPX processors for the context-building prefill stage while standard Rubin chips with huge HBM3e memory bandwidth handle the decode stage—he same principle EXO is already demonstrating on off-the-shelf hardware.
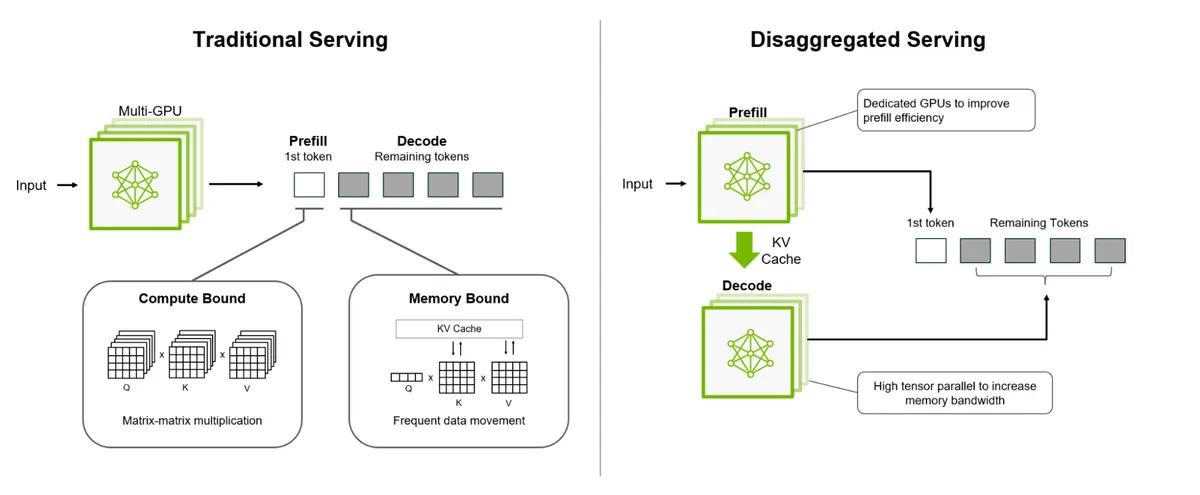
EXO's early-access release is still in the experimental stages. The current open-source version (0.0.15-alpha) dates back to March 2025, and the full 1.0 build — with automated scheduling, KV streaming, and heterogeneous optimizations — isn't public yet. It's not plug-and-play software for consumers, at least not yet; for now, it's a research-grade tool proving that disaggregated inference can deliver real gains.
Even so, it's an exciting proof of concept. By making intelligent use of mixed hardware, EXO shows that high-performance AI doesn't have to be monopolized by data centers. It's enough to make you wonder about the potential of the devices sitting around your office.

Follow Tom's Hardware on Google News, or add us as a preferred source, to get our latest news, analysis, & reviews in your feeds.
